Scrapy框架(一) 第一个Scrapy项目
前言
这几天在Scrapy框架里面挣扎了好久,各种碰坑,好在也懵懵懂懂的坚持了下来,话不多说,直接进入正题吧~
本篇博客框架如下: + 第一个Scrapy项目 + 编写爬虫 + 清理—item装载器与管理字段 + Scrapy Shell ******
一、第一个Scrapy项目
1.1 创建爬虫项目
打开cmd窗口,cd到你想存放项目的文件夹下,输入创建命令: > scrapy startproject projectname
其中projectname是爬虫项目名称
进入爬虫项目后,我们可以看到如下的项目结构: >│ scrapy.cfg │ └─projectname │ items.py │ pipelines.py │ settings.py │ init.py │ └─spiders init.py ···
1.2 创建爬虫
cd到刚才创建的项目下,输入创建爬虫命令: > scrapy genspider basic web
然后我们可以发现在projectname/spiders目录中增加了一个basic.py文件,这个命令所作的工作就是创建一个名为“basic” 的默认爬虫,并且该爬虫被限制为只能爬取web域名下的URL。
下面我通过创建一个名为Demo 的项目名以及demo 的默认爬虫进行演示
爬虫的演示网址为我一位朋友的博客:https://jcoffeezph.top/
二、编写爬虫
scrapy startproject Demo scrapy genspider demo web
创建项目完成后我们打开items.py和demo.py文件,效果如下: 

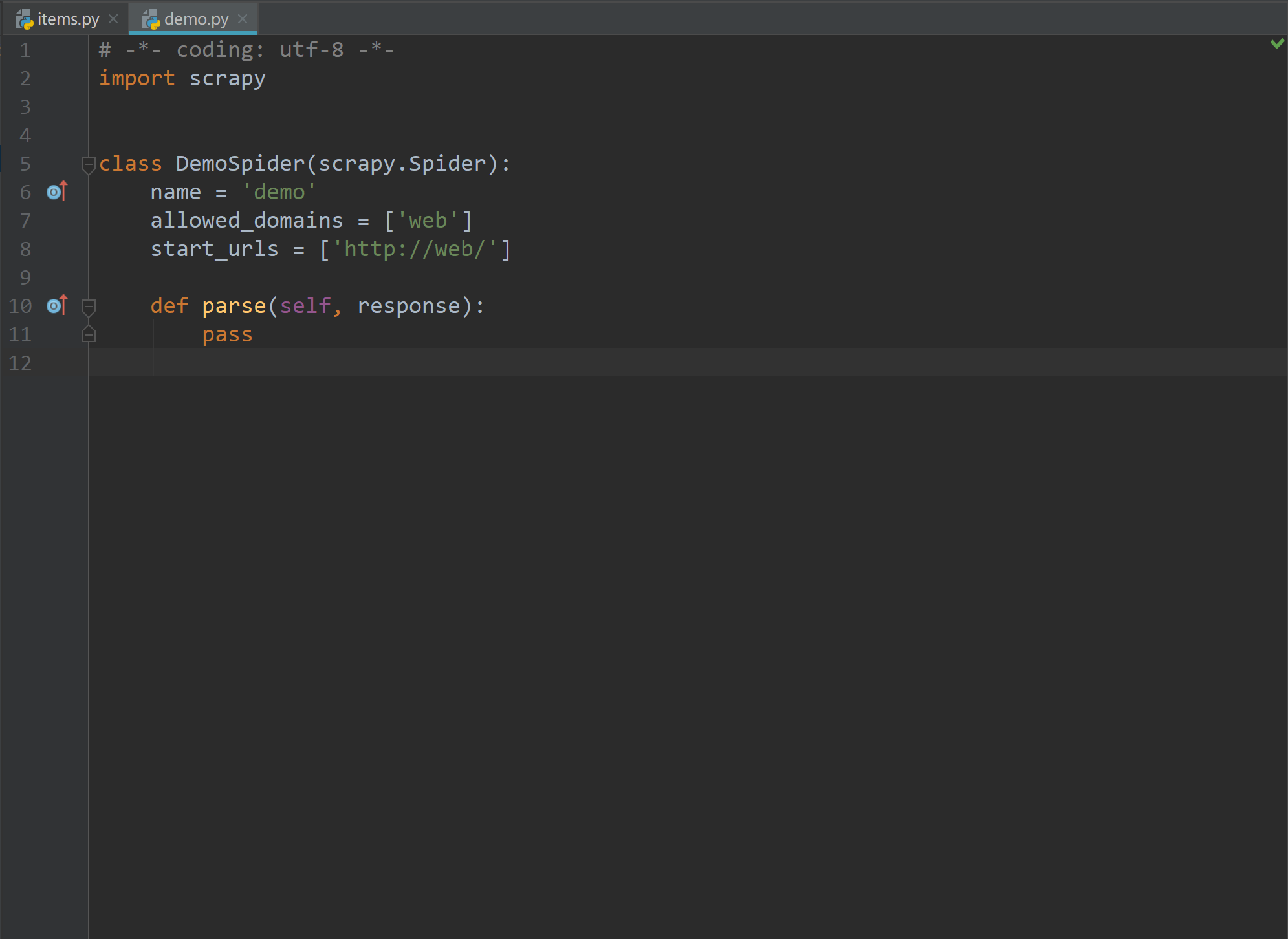
之后我们就要大展身手着手开始编写爬虫啦~首先介绍一下items.py这个文件。
1.items.py
使用items来包装需要爬取的内容。把内容都用items.py来进行管理,便于把抓取的内容传递进pipelines进行后期处理。同时,把内容都放进items.py以后,可以解耦合爬虫文件demo.py,责任更加明晰:爬虫负责去发请求,解析网址;items.py负责管理抓取到的内容。
在项目目录下有items.py文件。这是存放items的地方,也就是存放抓取内容的地方。我们需要在items.py中告诉Scrapy我们要抓取的内容叫什么名字,也就是需要声明items。
Item使用简单的class定义语法以及 Field 对象来声明。例如:  表示我们要抓取的内容是:title,time,author以及link。
表示我们要抓取的内容是:title,time,author以及link。
Field对象指明了每个字段的元数据(metadata),你可以为每个字段指明任何类型的元数据。 Field对象对接受的值没有任何限制。也正是因为这个原因,文档也无法提供所有可用的元数据的键(key)参考列表。 Field对象中保存的每个键可以由多个组件使用,并且只有这些组件知道这个键的存在。你可以根据自己的需求,定义使用其他的Field键。 设置 Field 对象的主要目的就是在一个地方定义好所有的元数据。 一般来说,那些依赖某个字段的组件肯定使用了特定的键(key)。您必须查看组件相关的文档,查看其用了哪些元数据键(metadata key)。
需要注意的是,用来声明item的Field对象并没有被赋值为class的属性。 不过您可以通过Item.fields属性进行访问。
2.demo.py
接下来我们进入demo.py
文件中。import语句能够让我们使用Scrapy框架中已有的类。下面是扩展自scrapy.Spider的DemoSpider类的定义。通过扩展的方式,尽管我们实际上没有写任何代码,但是该类已经继承了Scrapy框架中Spider类的相当一部分功能。这样,就可以只额外编写少量的代码行,而获得一个完整运行的爬虫了。最后是空函数parse()的定义,该函数包含两个参数self和response对象。通过self的引用,我们就可以使用爬虫中感兴趣的功能了。response对象是网页返回的请求对象。
首先,我们需要引入之前在item.py中编写的DemoItem类。如前所述,它在Demo目录的items.py文件中,也就是Demo.items模块中。我们使用如下命令引入该模块: > from Demo.items import DemoItem
然后需要进行实例化,并返回一个对象。这非常简单,在parse()方法中,可以通过添加 item = DemoItem() 语句创建一个新的item,然后可以按如下方式为其字段分配表达式: > item[‘title’] = response.xpath(’ ’).extract()
有关xpath的具体用法可以参考我之前的一篇博客:Xpath用法总结
- 最后return item返回item,代码如下所示:
1 | # -*- coding: utf-8 -*- |
写完之后保存,我们在cmd下cd进入Demo爬虫项目下,输入爬取命令: >scrapy crawl demo
可以在控制台看到如下输出:
1 | 2018-11-18 23:55:47 [scrapy.core.engine] INFO: Spider opened |
在爬取的同时我们也可以把数据保存到文件中,通过如下命令即可: > scrapy crawl demo -o items.json
三、清理—item装载器与管理字段
首先,我们使用一个强大的工具类——ItemLoader,以代替那些杂乱的extract()和xpath()操作。通过使用该类,我们的parse()方法会按如下进行代码变更:
1 | # -*- coding: utf-8 -*- |
好多了,是不是?不过,这种写法并不只是视觉上更加舒适,它还非常明确地声明了我们意图去做的事情,而不会将其与实现细节混淆起来。这就使得代码具有更好的可维护性以及自描述性。
ItemLoader提供了许多有趣的结合数据及对数据进行格式化和清洗的方式。处理器是一个快速而又简单的函数。处理器的一个例子是Join()。假设你已经使用类似//p 的xpath表达式选取了很多个段落,该处理器可以将这些段落结合成一个条目。另一个非常有意思的处理器是MapCompose(),通过使用该处理器,你可以使用任意Python函数或Python函数链,以实现复杂的功能。比如,MapCompose(float)可以将字符串数据转换为数值,而MapCompose(str.strip, str.title)可以删除多余的空白符,并将字符串格式化为每个单词均为首字母大写的样式。当然,你也可以通过lambda表达式自定义一些函数。
这里要解决的关键问题是,处理器只是一些简单小巧的功能,用来对我们的Xpath/CSS结果进行后置处理。现在,在爬虫中使用几个这样的处理器,并按照我们想要的方式输出,代码如下:
1 | # -*- coding: utf-8 -*- |
最后,我们可以通过使用add_value()方法,添加Python计算得出的单个值,我们可以用该方法设置“管理字段”,比如URL,爬虫名称,时间戳等。我们还可以直接使用管理字段表中总结出来的表达式:
1 | #举例 |
以上是ItemLoader及其功能的简要概述,ItemLoader和处理器是基于编写并支持了成千上万个爬虫的人们的抓取需求而开发的工具包,如果你准备开发多个爬虫的话,就非常值得去学习使用它们。 ****** ### 四、Scrapy Shell Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据。
如果安装了 IPython ,Scrapy终端将使用 IPython (替代标准Python终端)。 IPython 终端与其他相比更为强大,提供智能的自动补全,高亮输出,及其他特性。(推荐安装IPython)
4.1 启动Scrapy Shell
进入cmd,执行下列命令来启动shell: > scrapy shell “http://jcoffeezph.top”
会在控制台看到如下输出: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
442018-11-19 08:25:59 [scrapy.utils.log] INFO: Scrapy 1.5.1 started (bot: scrapybot)
2018-11-19 08:25:59 [scrapy.utils.log] INFO: Versions: lxml 4.2.3.0, libxml2 2.9.7, cssselect 1.0.3, parsel 1.5.0, w3lib 1.19.0, Twisted 18.7.0, Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)], pyOpenSSL 18.0.0 (OpenSSL 1.1.0h 27 Mar 2018), cryptography 2.3, Platform Windows-10-10.0.17134-SP0
2018-11-19 08:25:59 [scrapy.crawler] INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0}
2018-11-19 08:25:59 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole']
2018-11-19 08:25:59 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-11-19 08:25:59 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-11-19 08:25:59 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-11-19 08:25:59 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-11-19 08:25:59 [scrapy.core.engine] INFO: Spider opened
2018-11-19 08:26:00 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://jcoffeezph.top/> from <GET http://jcoffeezph.top>
2018-11-19 08:26:00 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://jcoffeezph.top/> (referer: None)
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x000001A0F9FF4898>
[s] item {}
[s] request <GET http://jcoffeezph.top>
[s] response <200 https://jcoffeezph.top/>
[s] settings <scrapy.settings.Settings object at 0x000001A0F9FF4C18>
[s] spider <DefaultSpider 'default' at 0x1a0fa284d68>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
In [1]: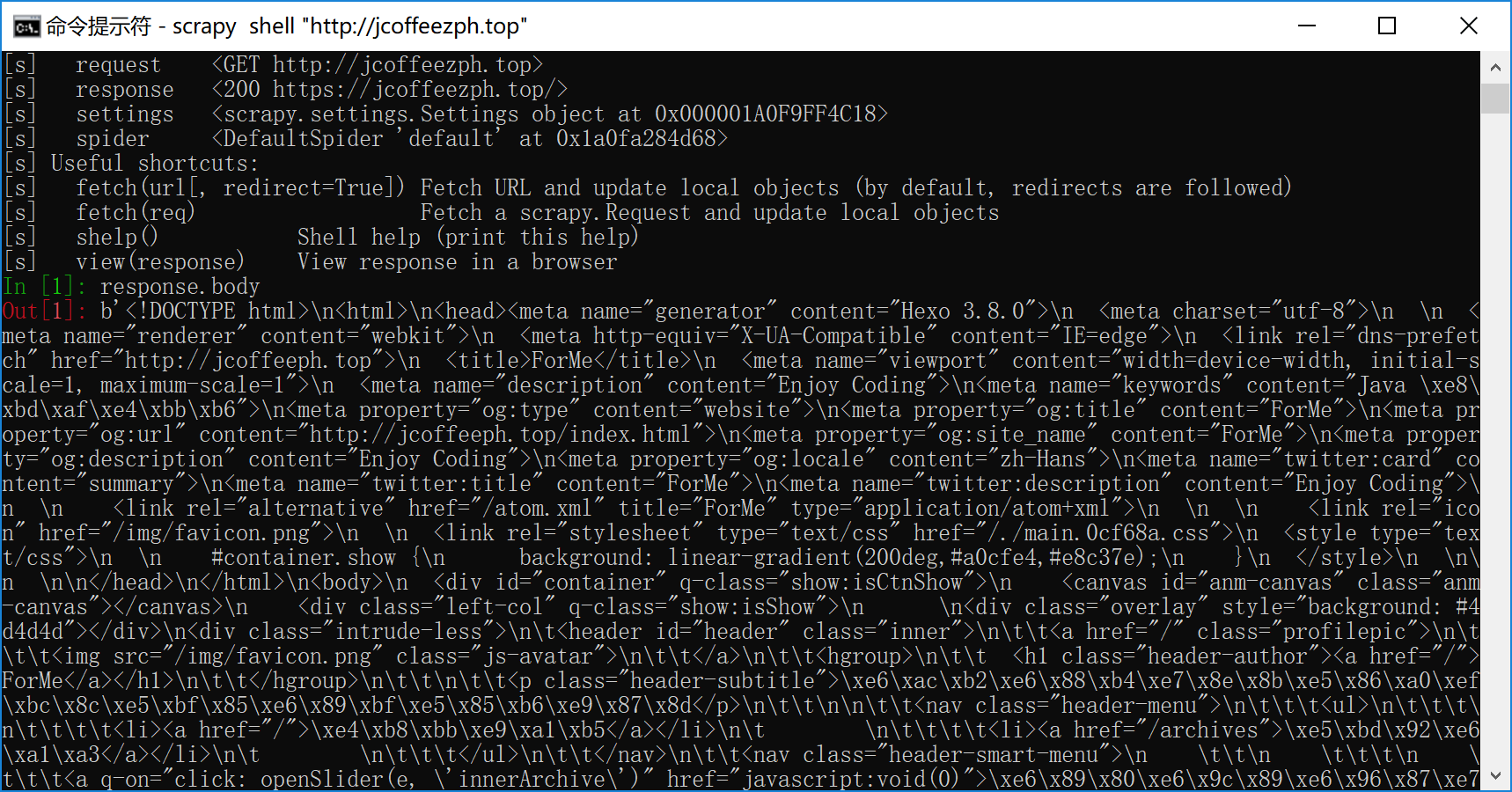
4.2 Selectors选择器
Scrapy Selectors 内置 XPath 和 CSS Selector 表达式机制
Selector有四个基本的方法,最常用的还是xpath:
- xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表
- extract(): 序列化该节点为Unicode字符串并返回list
- css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表,语法同BeautifulSoup4
- re(): 根据传入的正则表达式对数据进行提取,返回Unicode字符串list列表
4.3 XPath表达式的例子及对应的含义:
我们还是以演示博客 https://jcoffeezph.top/ 为例:
1 | In [4]: response.xpath('//*[@id="header"]/hgroup/h1/a/text()').extract() |
下面对4.3.1做几点解释: 1.
xpath表达式语法不做过多的说明,具体可以参考我的一篇博客:Xpath用法总结
2.
如果不使用extract(),response.xpath()的返回值是网页内容预加载的Selector对象,为了获取真实值,可以使用extract(),也可以使用re()。
1
2In [5]: response.xpath('//*[@id="header"]/hgroup/h1/a/text()')
Out[5]: [<Selector xpath='//*[@id="header"]/hgroup/h1/a/text()' data='ForMe'>]index out of range这个错,表示很奇怪,现在也不知道具体原因,pycharm中具体解决方法可以参考我的一篇博客:Scrapy框架之细数到目前为止我遇到的坑
以后做数据提取的时候,可以先在Scrapy Shell中测试,测试通过后再应用到代码中。而Scrapy Shell的主要作用也是用来测试xpath表达式。
当然Scrapy Shell作用不仅仅如此,但是不属于我们课程重点,不做详细介绍。