Scrapy框架(五) 将数据存储到数据库
一、前言
这章作为我最感兴趣的一章,当然要好好大写特写一番了!
因为本人对Mysql比较熟悉,Python也有Pymysql这个库可以和Mysql进行交互,所以这章主要就是介绍将数据存储到Mysql数据库的Pipeline。之前也听说过Scrapy和Mongodb数据库结合起来也很方便,有空的话以后学了再补上叭~
注:以下的演示都是基于本机上的操作,一些库名,表名,项目名什么的各位看官自己写就好啦! ****** ### 二、准备工作 我们首先需要创建或安装一些东西: + Mysql localhost新建数据库pysqltest,在该数据库下创建表单名为blog
- 安装pymysql用于连接Mysql服务器
如果对Mysql不熟悉或者需要补一下Pymysql操作的可以参考我的以下博客: 1. Mysql之增删改查
- Pymysql实现与数据库的交互 ****** ### 三、同步存储和异步存储 存储数据有两种方法:
同步存储:适用于数据爬取量较少的情况
异步存储: 适用于数据量较大的情况( 因为Scrapy爬取的速度快于数据库的插入速度,当数据量大时,就会出现阻塞,需要异步解决 )
3.1 同步存储
先来介绍一下什么是同步吧。同步方法调用一旦开始,调用者必须等到方法调用返回后,才能继续后续的行为,也就是说需要等待返回值或者响应。
同步存储利用pymysql与数据库进行交互就可以实现,看过那篇博客学会了pymysql之后,代码看上去就会变得非常简单了。下面的代码主要是Pipeline里面需要注意,其它的前几篇Scrapy博客都有讲解。
直接上代码: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72# items.py
import scrapy
class DemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
time = scrapy.Field()
author = scrapy.Field()
link = scrapy.Field()
# demo.py
# -*- coding: utf-8 -*-
import scrapy
from Demo.items import DemoItem
from scrapy.loader import ItemLoader
from scrapy.loader.processors import MapCompose,Join
from urllib.parse import urljoin
from scrapy.http import Request
from urllib.parse import unquote
class DemoSpider(scrapy.Spider):
name = 'demo'
allowed_domains = ['web']
start_urls = ['https://jcoffeezph.top/']
def parse(self, response):
URLS = response.xpath('//*[@class="extend next"]//@href').extract()
for url in URLS:
yield Request(urljoin(response.url,url),dont_filter=True)
content_urls = response.xpath('//*[@class="article-title"]/@href').extract()
for url in content_urls:
yield Request(urljoin(response.url,url),callback=self.parse_item,dont_filter=True)
def parse_item(self,response):
l = ItemLoader(item=DemoItem(),response=response)
l.add_xpath('title', '//*[@class="article-title"]/text()',MapCompose(str.strip))
l.add_xpath('author', '//*[@id="header"]/hgroup/h1/a/text()',MapCompose(str.strip))
l.add_xpath('time', '//*[@itemprop="datePublished"]/text()',MapCompose(str.strip))
l.add_value('link',unquote(response.url))
return l.load_item()
# pipelines.py
# 详情请见博客:Pymysql实现与数据库的交互
import pymysql
class DemoPipeline(object):
def __init__(self):
self.db = pymysql.connect(host="localhost",user="root",password="root",db="pysqltest")
self.cur = self.db.cursor()
def process_item(self,item,spider):
sql = "insert into blog(title,author,time,link) values(%s,%s,%s,%s);"
try:
self.cur.execute(sql,(item['title'],item['author'],item['time'],item['link']))
self.db.commit()
except Exception as e:
self.db.rollback()
print(e)
finally:
return item
def close_spider(self,spider):
self.db.close()
self.cur.close()
# settings.py
ITEM_PIPELINES = {
'Demo.pipelines.DemoPipeline': 300,
}
即可看到运行结果: 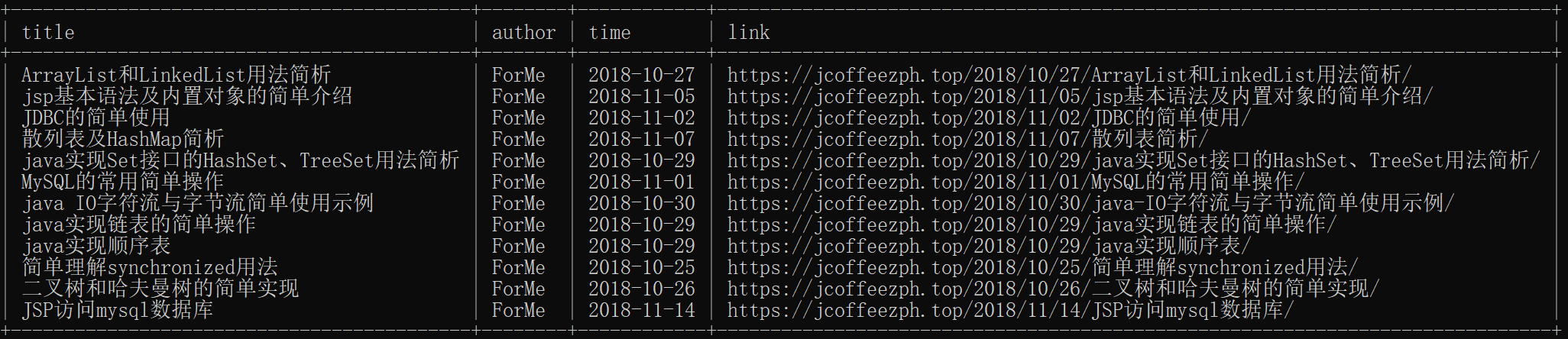
是不是很棒呢!
3.2 异步存储
再来介绍一下什么是异步吧。在同步中,单线程会遇到阻塞的情况,这个时候必须等待响应才能继续进行;而异步碰到阻塞时,阻塞会被挂起,线程继续执行下去,也就是获取下一个响应,遇到阻塞继续挂起,以此反复。可以明显的看到异步的执行速度比同步快出很多。
先贴一篇博客:Pymysql实现与数据库的交互里面对pymysql驱动访问数据库有很形象的比喻。
先上代码: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97# items.py
import scrapy
class DemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
time = scrapy.Field()
author = scrapy.Field()
link = scrapy.Field()
# demo.py
# -*- coding: utf-8 -*-
import scrapy
from Demo.items import DemoItem
from scrapy.loader import ItemLoader
from scrapy.loader.processors import MapCompose,Join
from urllib.parse import urljoin
from scrapy.http import Request
from urllib.parse import unquote
class DemoSpider(scrapy.Spider):
name = 'demo'
allowed_domains = ['web']
start_urls = ['https://jcoffeezph.top/']
def parse(self, response):
URLS = response.xpath('//*[@class="extend next"]//@href').extract()
for url in URLS:
yield Request(urljoin(response.url,url),dont_filter=True)
content_urls = response.xpath('//*[@class="article-title"]/@href').extract()
for url in content_urls:
yield Request(urljoin(response.url,url),callback=self.parse_item,dont_filter=True)
def parse_item(self,response):
l = ItemLoader(item=DemoItem(),response=response)
l.add_xpath('title', '//*[@class="article-title"]/text()',MapCompose(str.strip))
l.add_xpath('author', '//*[@id="header"]/hgroup/h1/a/text()',MapCompose(str.strip))
l.add_xpath('time', '//*[@itemprop="datePublished"]/text()',MapCompose(str.strip))
l.add_value('link',unquote(response.url))
return l.load_item()
# pipelines.py
# 使用twsited异步IO框架,实现数据的异步写入。
from twisted.enterprise import adbapi
from pymysql import cursors
class DemoPipeline(object):
def from_settings(cls,settings):
adbparams = dict(
host = settings['MYSQL_HOST'],
user = settings['MYSQL_USER'],
password = settings['MYSQL_PASSWORD'],
db = settings['MYSQL_DB'],
cursorclass = cursors.DictCursor,
)
# 初始化数据库连接池(线程池)
# 参数一:mysql的驱动
# 参数二:连接mysql的配置信息
dbpool = adbapi.ConnectionPool('pymysql',**adbparams)
return cls(dbpool)
def __init__(self,dbpool):
self.dbpool = dbpool
def process_item(self,item,spider):
# 在该函数内,利用连接池对象,开始操作数据,将数据写入到数据库中。
#使用twiest将mysql插入变成异步
# 参数1:在异步任务中要执行的函数insert_db;
# 参数2:给该函数insert_db传递的参数
query = self.dbpool.runInteraction(self.do_insert,item)
# 如果异步任务执行失败的话,可以通过ErrBack()进行监听, 给insert_db添加一个执行失败的回调事件
query.addErrback(self.handle_error)
return item
#处理异步的异常
def handle_error(self,failure):
print('failure')
#插入函数
def do_insert(self,cursor,item):
sql = "insert into blog(title,author,time,link) values(%s,%s,%s,%s);"
cursor.execute(sql,(item['title'],item['author'],item['time'],item['link']))
# 在execute()之后,不需要再进行commit(),连接池内部会进行提交的操作。
# settings.py
ITEM_PIPELINES = {
'Demo.pipelines.DemoPipeline': 300,
}
MYSQL_HOST = "localhost"
MYSQL_DB = "pysqltest"
MYSQL_USER = "root"
MYSQL_PASSWORD = "root"
下面对程序做几点说明:
1.@classmethod 一般来说,要使用某个类的方法,需要先实例化一个对象再调用方法。 而使用@classmethod,就可以不需要实例化,直接 类名.方法名() 来调用。 这有利于组织代码,把某些应该属于某个类的函数给放到那个类里去,同时有利于命名空间的整洁。 @classmethod也不需要self参数,第一个参数需要是表示自身类的cls参数。
2.将数据存储到数据库,我们首先要做的是和数据库进行连接。我们定义了from_settings这个类方法,并且在里面通过adbapi.ConnectionPool 生成数据库连接池,就好比同步存储中的connect()一样。那什么是数据库连接池呢? 每次对数据库进行操作时,重新获取数据库连接时间消耗等比较大,可以建立一个连接池保存一定数量的连接,当有对象需要数据库连接时,直接将这个连接返回给该对象,不再用重新获取数据库连接,加载驱动等;在初始化连接池对象时加载一次驱动,后面都不再需要加载驱动。差不多就是这个意思。它接受两个参数,一个是数据库驱动,你要访问什么数据库就需要什么样的驱动,这里我们访问mysql就用到了pymysql模块;第二个参数是一个字典,里面包括一些数据库服务器,用户名,密码,库名等信息。可以发现,与pymysql.connect()类似。
3.关于adbparams字典,我们首先需要将一些信息存入settings.py,方便调用它们,可以看到上面的settings.py文件。还有一点需要注意的是,key值的名字都是固定的,比如cursorclass等,如果擅自修改会报错:TypeError: init() got an unexpected keyword argument ‘cursor’。
4.我们通过cls(dbpool)返回类对象,同时会调用构造函数,对属性进行赋值。OK, dbpool连接池属性生成成功,Mysql连接成功!
5.下面程序来到了process_item(self,item,spider)这个必须函数,在这个函数中,我们做了两件事:第一件事就是通过runInteraction()将存储变成异步存储;第二件事就是常见的事故处理方法,通过ErrBack()进行监听, 给insert_db添加一个执行失败的回调事件。
6.定于插入函数do_insert 和异常处理函数handle_error 。运行程序,OK大功告成!
其实刚看这段程序还是花了我不少时间的,自己学着去理解程序的运行思路,还是自己面向对象这边的知识不扎实啊!!还是需要继续加油!!
有机会看看能不能搞一篇Mongodb出来叭~~