我的推荐算法之路(12):TDAR
一、前言
由于在电子商务和视频网站等各种在线平台上的普遍应用,推荐系统获得了广泛的研究关注。在实际应用中,隐式反馈数据(一类数据,如点击和购买等)被广泛使用,因为它易于收集且普遍适用。实际应用中的推荐通常存在严重的稀疏性问题,这会导致两个困难:
- 没有足够的交互来为模型学习提供信息。此外,数据高度不平衡:大多数用户和物品与系统只有很少的交互,这使得推荐任务更加困难。
- 由于我们在隐式反馈中只观察到一小部分正样本,现有的负采样策略是将未观察到的样本视为负样本。然而,通过这种方式,许多潜在的正样本被错误地标记为负样本,并且模型被标签噪声严重误导,尤其是在稀疏数据上。
为了解决上述挑战,我们采用迁移学习来丰富稀疏数据集上的信息,并且我们专注于没有用户和物品重叠的跨域推荐。具体来说,我们分别在稠密和稀疏数据上训练源模型和目标模型,并探索域自适应以对齐embeddings(即隐向量 latent factors),这是协同过滤 (CF) 模型中对用户偏好进行编码的关键组成部分。然而,在基本的 CF 模型中,没有具有特定语义的数据(例如图像和文本),我们通过将用户和物品嵌入(embedding)到潜在空间中来提取高级的密集特征。通过这种方式,我们将来自不同领域的用户和物品映射到不同的潜在空间。为了对齐潜在空间,我们探索域不变特征作为锚点。在本文中,我们利用了可以从用户评论(review)中轻松提取的文本特征。将文本特征与embeddings拼接起来,从而将空间扩展为文本潜在空间。对于域自适应,我们使用连接的embeddings和文本特征作为域分类器的输入。embeddings使用分类器进行对抗训练,而文本特征则固定。
正如我们所见,在我们的策略中,文本特征应该是域不变的,例如,来自所有域的恐怖电影都映射到文本空间的负半轴。现有的许多模型 提取文本特征用于推荐,而这些特征不是域不变的。为了缩小这一差距,首先,我们提出了一种称为文本记忆网络 ( Text Memory Network,TMN) 的记忆结构,通过将每个用户和物品映射到单词语义空间(word semantic space)来提取文本特征;然后,我们将这些特征注入 CF 模型以生成预测,这个由文本特征和CF模块组成的模型被命名为文本协同过滤(Text Collaborative Filtering,TCF)模型;最后,我们在源域和目标域上同步训练两个 TCF 模型,并通过自适应网络将它们连接起来。这个迁移学习模型被命名为文本增强域自适应推荐 (Text-enhanced Domain Adaptation Recommendation,TDAR) 方法。
原文链接:Semi-supervised Collaborative Filtering by Text-enhanced Domain Adaptation
二、Text Memory Network(TMN)
在本文中,粗体大写字母表示矩阵。假设总共有 \(M\) 个用户和 \(N\) 个物品,我们使用矩阵 \(R\) 来表示用户和物品之间的交互。如果用户 \(u\) 投票给物品 \(i\),则 \(R_{ui}=1\) ,否则 \(R_{ui}=0\)。我们的任务是对缺失值( \(R\) 中的 0 )进行预测(表示为 \(\hat{R}\) )。在本节中,我们根据评论构建特定用户和特定物品的文本表示,我们分别提取源域和目标域的文本特征。
以用户 \(u\) 为例,我们构造了一个评论集\(R_u=\mathop{\cup}\limits_{i=1}^{N}r_{ui}\) ,其中 \(r_{ui}\) 是一个包含 \(u\) 对 \(i\) 的评论的词的集合。如果 \(u\) 与 \(i\) 没有交互,则 \(r_{ui}=0\)。类似地,物品 \(i\) 的评论集是 \(R_i=\mathop{\cup}\limits_{u=1}^{M}r_{ui}\)。我们用 \(W\) 来表示词集:\(W=\mathop{\cup}\limits_{u=1}^M\mathop{\cup}\limits_{i=1}^Nr_{ui}\) ,用 \(H\) 来表示词的总数:\(H=|W|\) 。由于我们想要提取域不变的文本特征(即来自所有域的特征都在同一空间中),我们通过线性组合评论的词语义(word semantic)向量将所有用户和物品映射到词语义空间。
\(S\) 是word2vec在GoogleNews语料库上预训练的词语义矩阵, \(S_w\) 表示词 \(w\) 的语义特征。我们使用 \(E\) 和 \(F\) 分别表示我们为用户和物品构建的文本特征。以用户 \(u\) 为例,\(E_u=\mathop{\sum}\limits_{w\in R_u}a_{uw}S_w\) ,其中 \(a_{uw}\) 是词 \(w\) 基于 \(u\) 的语义偏好的权重。我们提出了一个文本记忆网络 (TMN) 来计算用户 \(a_{uw}\) 和物品 \(a_{iv}\) 的权重,以根据单词语义构建文本特征。
对一个喜欢恐怖电影的用户 \(u\) ,\(u\) 可能更喜欢相关的词(比如“horrible”、“frightened”、“terrifying”),对不相关的词(比如“this”、“is”、“a”)和相反的词(如“funny”、“relaxing”、“comical”)没兴趣。 对于 \(u\) 偏爱的词 \(w\),我们需要为 \(w\) 设置一个很大的权重 \(a_{uw}\)。在物品方面,对于恐怖片 \(i\),\(i\) 的评论中的相关词提供了很多关于 \(i\) 的信息,而不相关或相反的词提供的信息很少。针对对 \(i\) 很重要的词 \(v\),我们需要设置一个很大的权重 \(a_{iv}\)。容易看出,在这个任务中,我们的目标是向用户和物品推荐偏好词 (preferred words)。
受矩阵分解的启发,我们分别为用户、物品和单词声明了三个矩阵 \(P,Q,T\)。 以用户为例,我们使用 \(e_{uw}=P_uT^T_w\) 来建模 \(u\) 对单词 \(w\) 的偏好。 为了进一步强调重要的词,我们将 \(e_{uw}\) 输入到 softmax 函数中以获得 \(a_{uw}\),\(a_{uw}=\frac{exp(e_{uw})}{\mathop{\sum}\limits_{w'\in R_u}exp(e_{uw'})}\) 。 针对物品 \(a_{iv}\) 的权重以相同的方式构造。 我们最终通过 \(\hat{R}=\sigma(EF^T)\) 来预测用户对物品的偏好,我们使用交叉熵损失作为我们的损失函数:
\[L=-\mathop{\sum}\limits_{u,i}R_{ui}log\hat{R}_{ui}+(1-R_{ui})log(1-\hat{R}_{ui})\]
\[\hat{R}_{ui}=\sigma[(\mathop{\sum}\limits_{w\in R_u}\frac{exp(P_uT_w^T)}{\mathop{\sum}\limits_{w'\in R_u}exp(P_uT_{w'}^T)})(\mathop{\sum}\limits_{v\in R_i}\frac{exp(Q_iT_v^T)}{\mathop{\sum}\limits_{v'\in R_i}exp(Q_iT_{v'}^T)})]\]
三、文本增强跨域推荐
在通过 TMN 提取文本特征后,我们将在本节中介绍我们的文本增强域自适应推荐 (TDAR) 模型。 首先,我们将文本特征注入到 CF 模型中以提出基本的 TCF 模型。 然后,我们同时在目标域和源域上训练两个 TCF 模型,并通过域自适应对齐用户和物品嵌入。
3.1 文本协同过滤TCF
记 \(U,V\) 分别是用户和物品的embedding向量构成的矩阵。我们连接embedding和文本特征,因此用户和物品的表示是 \([U,E]\) 和 \([V,F]\)。我们用以下公式预测用户偏好:
\[\hat{R}_{ui}=f([U,E]_u,[V,F]_i,\Theta)\]
其中,\(f(\cdot,\Theta)\) 是结合用户和物品 embedding 并返回偏好预测的交互函数,\(\Theta\) 表示参数。 我们通过最小化交叉熵来学习模型。在这个模型中,\(U,V,\Theta\) 是可训练的参数, 而 \(E\) 和 \(F\) 是固定的。
3.2 文本增强域自适应推荐
在本小节中,我们使用上标 \(s,t,u,i\) 分别表示源域、目标域、用户和物品。\(R_s\) 和 \(R_t\) 表示源域和目标域上的交互。 我们在两个域上训练两个 TCF,同时共享相同的交互函数,因此对两个域中数据集的预测由下式给出:
\[\hat{R}_{u^si^s}^s=f([U^s,E^s]_{u^s},[V^s,F^s]_{i^s},\Theta)\]
\[\hat{R}_{u^ti^t}^t=f([U^t,E^t]_{u^t},[V^t,F^t]_{i^t},\Theta)\]
然后我们在两个 TCF 上添加自适应网络以实现迁移学习。 考虑到用户和物品 embedding 的分布模式可能不同,我们分别对用户和物品通过DANN模型的思想进行域自适应(有关DANN的介绍参见我的推荐算法之路(11):DANN与DARec)。TDAR模型结构如下图所示:
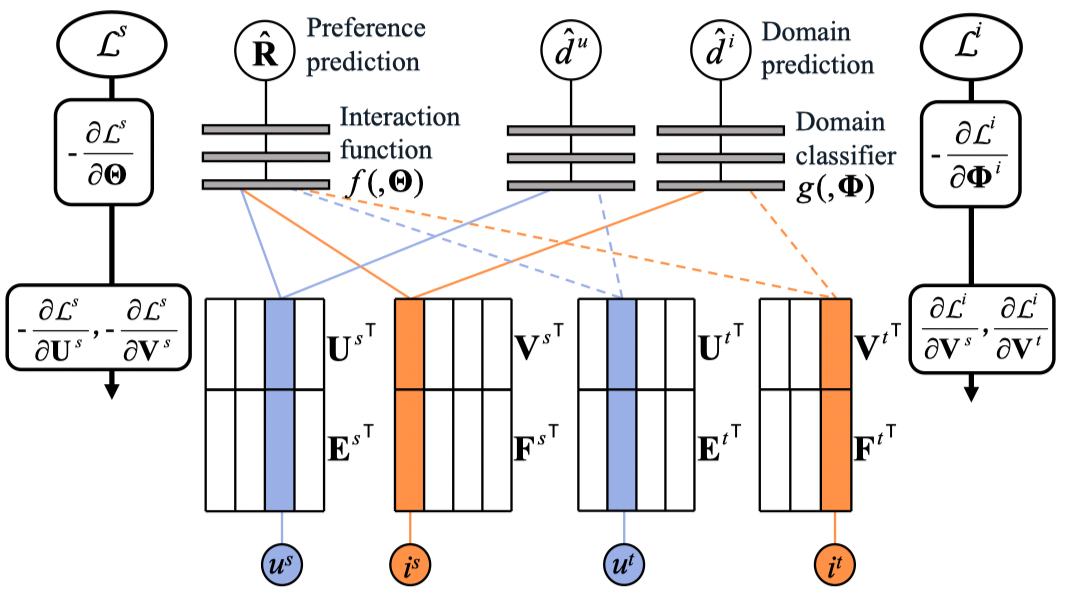
在 TDAR 中,两个基本模型由标签和域分类器共同监督。 正如前文中所讨论的,目标域上的负标签受噪声严重污染,但正标签是纯净的,因此我们放弃了负样本。不幸的是,在隐式反馈案例中仅使用正样本进行监督会导致一个新问题——该模型倾向于将所有项目预测为正项目。为了解决这个问题,我们利用域自适应机制来监督目标域上的基本模型以及正样本。 但是,作为双域系统,需要对整个系统进行负采样。 考虑到源域通常比目标域密集得多,负标签的质量要高得多,我们采用源域进行负监督,并通过域适应将负监督转移到目标域。
对于文本特征 \(E\) 和 \(F\) ,我们可以在 TDAR 训练期间预训练并固定它们,也可以从头开始与TDAR联合训练。 实验表明,联合训练使模型更难以调优,且没有实现性能提升,因此我们选择了前一种策略。 实验还表明,与学习用户和物品 embedding 相比,学习到的文本特征对标签噪声的鲁棒性要强得多。
四、参考链接
- https://zhuanlan.zhihu.com/p/424639071