新篇 精通Python爬虫框架Scrapy
 ### 前言
很早之前学习了《Python网络数据采集》这本爬虫入门书籍,书上基本用的是Python标准库urllib和第三方库BeautifulSoup,还有一些少量的requests库。过了这么长时间,对爬虫也不是很熟悉了。想了想以后可能会从事大数据方面的工作,本人对数据也是hin感兴趣。于是想腾出时间学习一下Scrapy框架,也趁此机会巩固一下我的爬虫能力。
### 前言
很早之前学习了《Python网络数据采集》这本爬虫入门书籍,书上基本用的是Python标准库urllib和第三方库BeautifulSoup,还有一些少量的requests库。过了这么长时间,对爬虫也不是很熟悉了。想了想以后可能会从事大数据方面的工作,本人对数据也是hin感兴趣。于是想腾出时间学习一下Scrapy框架,也趁此机会巩固一下我的爬虫能力。
这本《精通Python爬虫框架Scrapy》基于Scrapy1.0和Python2.x版本,虽然我学的是Python3.x,但这本书应该不会影响阅读,之后的博客就会基于这本书发布一些我学习Scrapy的进度,理解等等,路还很长,一起加油吧! ****** ### 什么是Scrapy?
Scrapy 是用 纯Python 实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted 异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
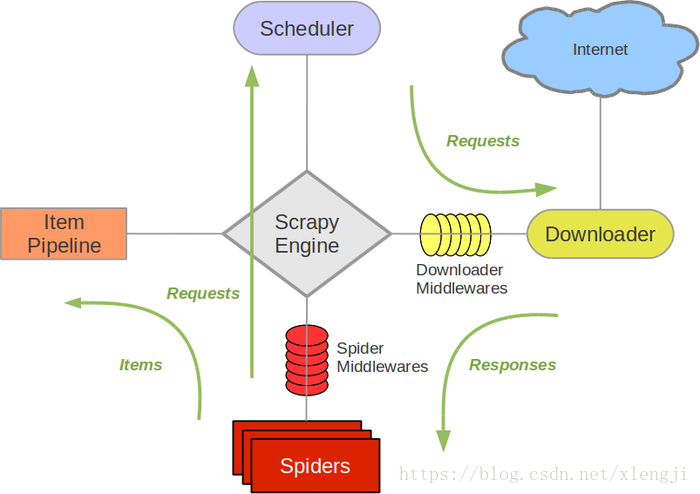
Scrapy架构图:
Python3.6.4及以上已经支持Scrapy了,因此我们可以直接通过pip安装。
pip install scrapy
升级Scrapy
pip install –upgrade scrapy ******
