MySQL之增删改查
运行MySQL
如果没有开启Mysql服务需输入net start mysql;命令
1: cd 到mysql bin目录下: 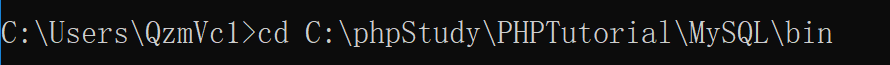
2:链接到本地数据库: 
-h localhost表示链接到本地数据库,-u表示数据库用户名(默认为root),-p表示数据库密码(默认为root) 3:导入sql文件 >mysql>create database dbname; >mysql>show databases; >mysql>use dbname; >mysql>source c:.sql
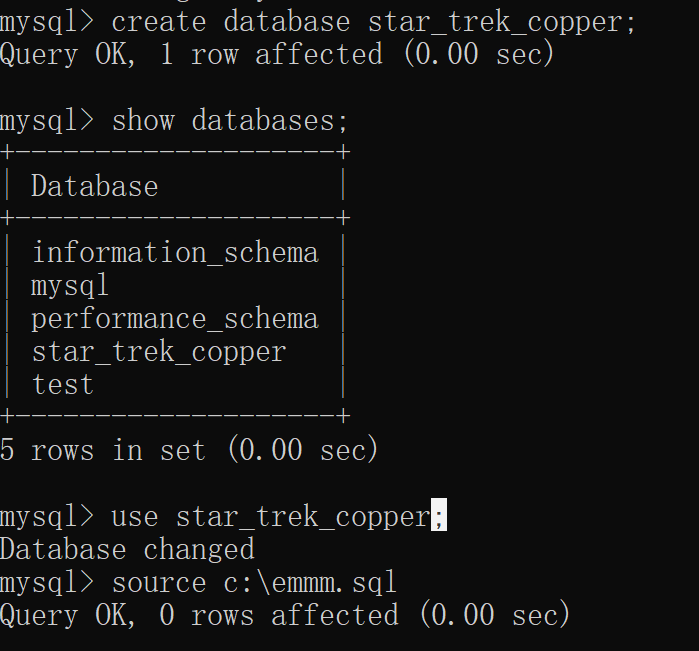
4: 删除数据库 >drop database dbname;
5:创建表单: 1
2
3
4
5
6
7
8CREATE TABLE doubanmovie (
name VARCHAR(100) NOT NULL, # 电影名字
info VARCHAR(150), # 电影信息
rating VARCHAR(10), # 评分
num VARCHAR(10), # 评论人数
quote VARCHAR(100), # 经典语句
img_url VARCHAR(100), # 电影图片
)default charset=utf8;
数据库操作增删改查:
1. 增
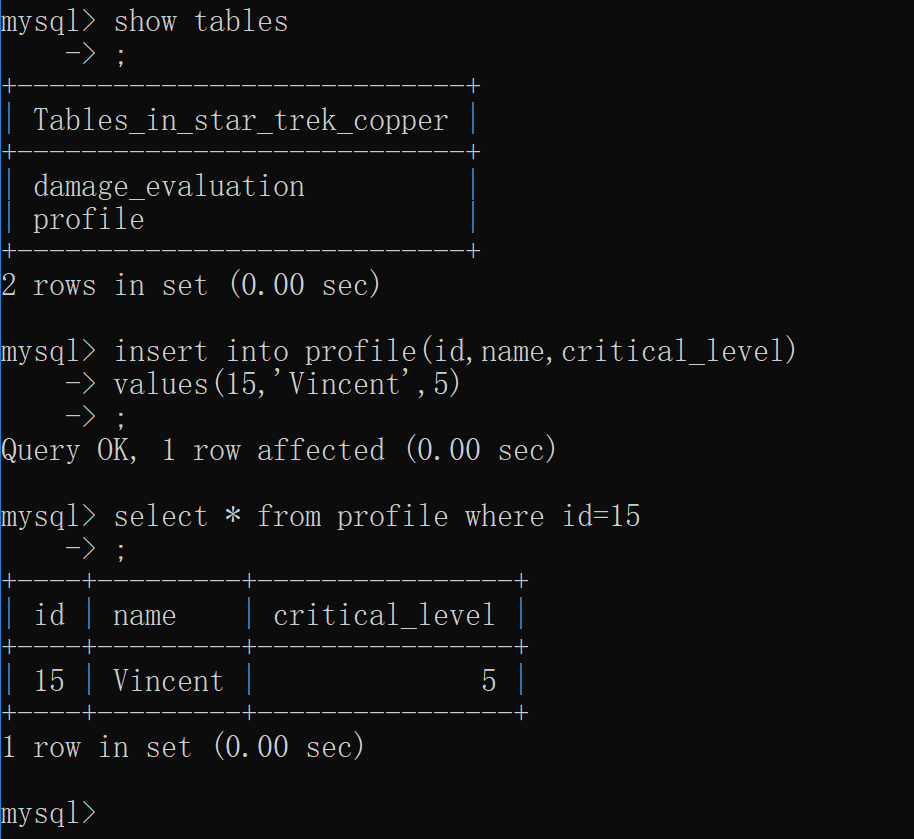
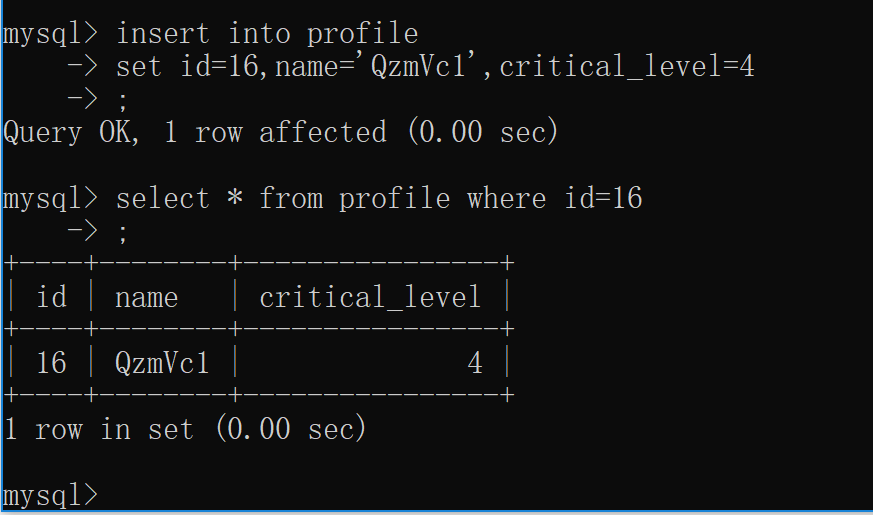 ****** ####
2. 删 ##### 2.1 删除部分记录
****** ####
2. 删 ##### 2.1 删除部分记录 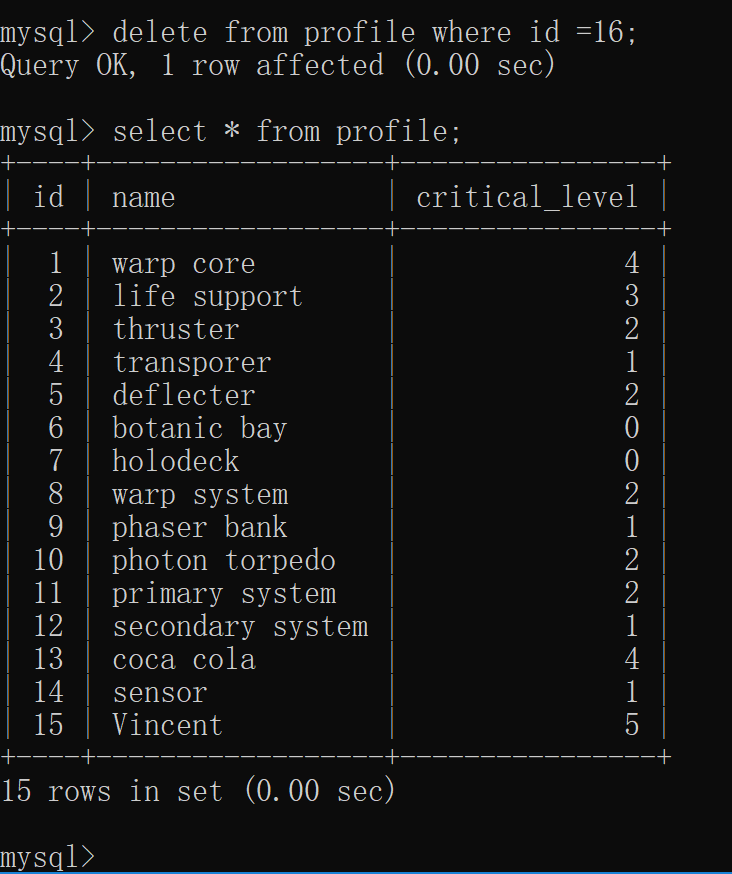
2.2 删除全部记录
 ****** ####
3. 改 ##### 3.1 更新部分数据
****** ####
3. 改 ##### 3.1 更新部分数据 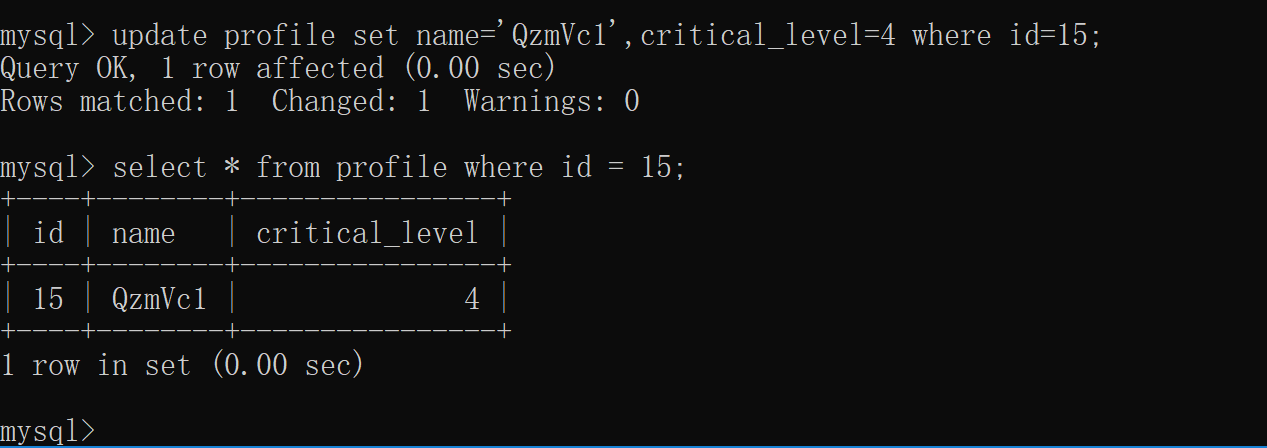
3.2 更新全部数据
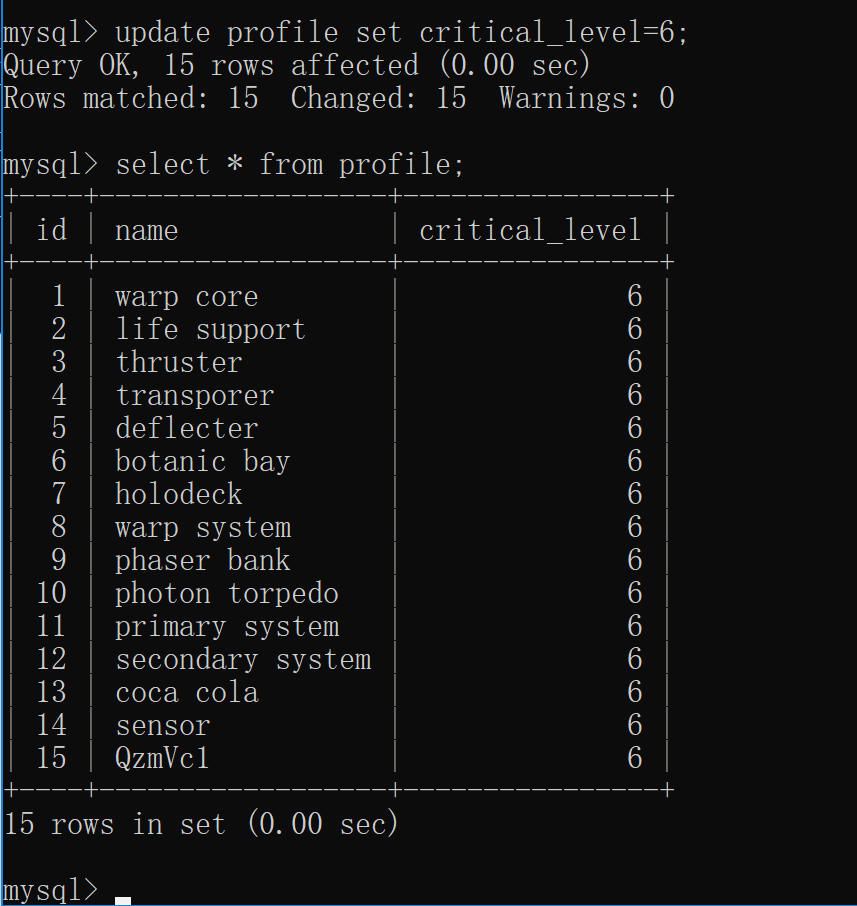 ****** ####
4. 查 ##### 4.1 查询所有字段 >select
字段名1,字段名2,… from 表名
****** ####
4. 查 ##### 4.1 查询所有字段 >select
字段名1,字段名2,… from 表名
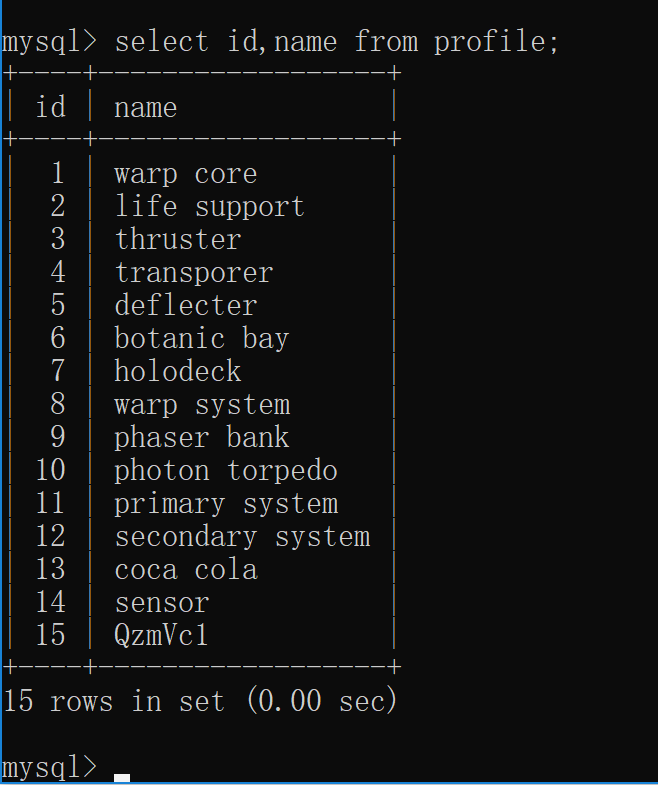
4.2 在select语句中使用(’*’)通配符代替所有字段
select * from 表名;
4.3 查询指定的部分字段
语法:select 字段名1,字段名2,… from 表名; 举例:查询student2表中的name字段和gender字段 命令:select name,gender from student2;
4.4 带关系运算符的查询
select 字段名1,字段名2,… from 表名 where 条件表达式
4.5 带 BETWEEN AND 关键字的查询
between and 用于判断某个字段的值是否在指定范围之内,若在,则该字段所在的记录会被查询出来,反之不会。
语法:select { 字段名1,字段名2,… } from 表名 where 字段名 [ not ] between 值 1 and 值 2; 举例:查询student2表中id值在2~5之间的人的id和name 命令:select id,name from students where id between 2 and 5;
4.6 带 distinct 关键字的查询
很多表中某些字段的数据存在重复的值,可以使用DISTINCT关键字来过滤重复的值,只保留一个值。
语法:SELECT DISTINCT 字段名 FROM 表名; 举例:查询student2表中gender字段的值,结果中不允许出行重复的值。 命令:SELECT DISTINCT gender FROM student2;
4.7 带 LIKE 关键字的查询
语法:SELECT * | 字段名1,字段名2,… FROM 表名 WHERE 字段名 [ NOT ] LIKE ‘匹配字符串’;
(1)百分号(%)通配符 匹配任意长度的字符串,包括空字符串。例如,字符串“ c% ”匹配以字符 c 开始,任意长度的字符串,如“ ct ”,“ cut ”,“ current ”等;字符串“ c%g ”表示以字符 c 开始,以 g 结尾的字符串;字符串“ %y% ”表示包含字符“ y ”的字符串,无论“ y ”在字符串的什么位置。
举例1:查询student2表中name字段以字符“ s ”开头的人的id,name 命令:SELECT id,name FROM student2 WHERE name LIKE “S%”;
举例2:查询student2表中name字段以字符“ w ”开始,以字符“ g ”结尾的人的id,name。 命令:SELECT id,name FROM student2 WHERE name LIKE ‘w%g’;
举例3:查询student2表中name字段不包含“ y ”的人的id,name。 命令:SELECT id,name FROM student2 WHERE name NOT LIKE ‘%y%’;
(2)下划线通配符 >下划线通配符只匹配单个字符,若要匹配多个字符,需要使用多个下划线通配符。例如,字符串“ cu_ ”匹配以字符串“ cu ”开始,长度为3的字符,如“ cut ”,“ cup ”;字符串“ c__l”匹配在“ c ”和“ l ”之间包含两个字符的字符串,如“ cool ”。
举例:查询在student2表中name字段值以“ wu ”开始,以“ ong ”结束,并且中间只有一个字符的记录。 命令:SELECT * FROM student2 WHERE name LIKE ‘wu_ong’;
高级查询
(1)COUNT()函数:统计记录的条数 >举例:查询student2表中一共有多少条记录 命令:SELECT COUNT(*) FROM student2;
(2)SUM()函数:求出表中某个字段所有值的总和 >语法:SELECT SUM(字段名) FROM 表名; 举例:求出student2表中grade字段的总和 命令:SELECT SUM(grade) FROM student2;
(3)AVG()函数:求出表中某个字段所有值的平均值 >语法:SELECT AVG(字段名) FROM 表名; 举例:求出student2表中grade字段的平均值 命令:SELECT AVG(grade) FROM student2;
(4)MAX()函数:求出表中某个字段所有值的最大值 >语法:SELECT MAX(字段名) FROM 表名; 举例:求出student2表中所有人grade字段的最大值 命令:SELECT MAX(grade) FROM student2;
(5)MIN()函数:求出表中某个字段所有值的最小值 >语法:SELECT MIN(字段名) FROM 表名; 举例:求出student2表中所有人grade字段的最小值 命令:SELECT MIN(grade) FROM student2;
对查询结果进行排序
语法:SELECT 字段名1,字段名2,… FROM 表名 ORDER BY 字段名1 [ ASC | DESC ],字段名2 [ ASC|DESC ]… 在该语法中指定的字段名是对查询结果进行排序的依据,ASC表示升序排列,DESC 表示降序排列,默认情况是升序排列。 >举例1:查出student2表中的所有记录,并按照grade字段进行降序排序 >命令:SELECT * FROM student2 ORDER BY grade DESC;