1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| 2018-11-19 11:02:57 [scrapy.core.engine] INFO: Spider opened
2018-11-19 11:02:57 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-11-19 11:02:57 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-11-19 11:02:58 [scrapy.core.engine] DEBUG: Crawled (404) <GET https://jcoffeezph.top/robots.txt> (referer: None)
2018-11-19 11:02:59 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://jcoffeezph.top/> (referer: None)
2018-11-19 11:02:59 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://jcoffeezph.top/page/2/> (referer: https://jcoffeezph.top/)
2018-11-19 11:02:59 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://jcoffeezph.top/2018/10/29/java%E5%AE%9E%E7%8E%B0Set%E6%8E%A5%E5%8F%A3%E7%9A%84HashSet%E3%80%81TreeSet%E7%94%A8%E6%B3%95%E7%AE%80%E6%9E%90/> (referer: https://jcoffeezph.top/)
2018-11-19 11:02:59 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://jcoffeezph.top/2018/11/01/MySQL%E7%9A%84%E5%B8%B8%E7%94%A8%E7%AE%80%E5%8D%95%E6%93%8D%E4%BD%9C/> (referer: https://jcoffeezph.top/)
2018-11-19 11:03:00 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://jcoffeezph.top/2018/10/29/java%E5%AE%9E%E7%8E%B0%E9%A1%BA%E5%BA%8F%E8%A1%A8/> (referer: https://jcoffeezph.top/)
2018-11-19 11:03:00 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://jcoffeezph.top/2018/11/02/JDBC%E7%9A%84%E7%AE%80%E5%8D%95%E4%BD%BF%E7%94%A8/> (referer: https://jcoffeezph.top/)
2018-11-19 11:03:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://jcoffeezph.top/2018/11/01/MySQL%E7%9A%84%E5%B8%B8%E7%94%A8%E7%AE%80%E5%8D%95%E6%93%8D%E4%BD%9C/>
{'author': ['ForMe'], 'time': ['2018-11-01'], 'title': ['MySQL的常用简单操作']}
2018-11-19 11:03:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://jcoffeezph.top/2018/10/29/java%E5%AE%9E%E7%8E%B0Set%E6%8E%A5%E5%8F%A3%E7%9A%84HashSet%E3%80%81TreeSet%E7%94%A8%E6%B3%95%E7%AE%80%E6%9E%90/>
{'author': ['ForMe'],
'time': ['2018-10-29'],
'title': ['java实现Set接口的HashSet、TreeSet用法简析']}
2018-11-19 11:03:00 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://jcoffeezph.top/2018/11/14/JSP%E8%AE%BF%E9%97%AEmysql%E6%95%B0%E6%8D%AE%E5%BA%93/> (referer: https://jcoffeezph.top/)
2018-11-19 11:03:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://jcoffeezph.top/2018/10/29/java%E5%AE%9E%E7%8E%B0%E9%A1%BA%E5%BA%8F%E8%A1%A8/>
{'author': ['ForMe'], 'time': ['2018-10-29'], 'title': ['java实现顺序表']}
2018-11-19 11:03:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://jcoffeezph.top/2018/11/02/JDBC%E7%9A%84%E7%AE%80%E5%8D%95%E4%BD%BF%E7%94%A8/>
{'author': ['ForMe'], 'time': ['2018-11-02'], 'title': ['JDBC的简单使用']}
2018-11-19 11:03:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://jcoffeezph.top/2018/11/14/JSP%E8%AE%BF%E9%97%AEmysql%E6%95%B0%E6%8D%AE%E5%BA%93/>
{'author': ['ForMe'], 'time': ['2018-11-14'], 'title': ['JSP访问mysql数据库']}
2018-11-19 11:03:00 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://jcoffeezph.top/2018/10/26/%E4%BA%8C%E5%8F%89%E6%A0%91%E5%92%8C%E5%93%88%E5%A4%AB%E6%9B%BC%E6%A0%91%E7%9A%84%E7%AE%80%E5%8D%95%E5%AE%9E%E7%8E%B0/> (referer: https://jcoffeezph.top/page/2/)
2018-11-19 11:03:00 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://jcoffeezph.top/2018/11/07/%E6%95%A3%E5%88%97%E8%A1%A8%E7%AE%80%E6%9E%90/> (referer: https://jcoffeezph.top/)
2018-11-19 11:03:00 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://jcoffeezph.top/2018/10/25/%E7%AE%80%E5%8D%95%E7%90%86%E8%A7%A3synchronized%E7%94%A8%E6%B3%95/> (referer: https://jcoffeezph.top/page/2/)
2018-11-19 11:03:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://jcoffeezph.top/2018/10/26/%E4%BA%8C%E5%8F%89%E6%A0%91%E5%92%8C%E5%93%88%E5%A4%AB%E6%9B%BC%E6%A0%91%E7%9A%84%E7%AE%80%E5%8D%95%E5%AE%9E%E7%8E%B0/>
{'author': ['ForMe'], 'time': ['2018-10-26'], 'title': ['二叉树和哈夫曼树的简单实现']}
2018-11-19 11:03:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://jcoffeezph.top/2018/11/07/%E6%95%A3%E5%88%97%E8%A1%A8%E7%AE%80%E6%9E%90/>
{'author': ['ForMe'], 'time': ['2018-11-07'], 'title': ['散列表及HashMap简析']}
2018-11-19 11:03:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://jcoffeezph.top/2018/10/25/%E7%AE%80%E5%8D%95%E7%90%86%E8%A7%A3synchronized%E7%94%A8%E6%B3%95/>
{'author': ['ForMe'], 'time': ['2018-10-25'], 'title': ['简单理解synchronized用法']}
2018-11-19 11:03:00 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://jcoffeezph.top/2018/11/05/jsp%E5%9F%BA%E6%9C%AC%E8%AF%AD%E6%B3%95%E5%8F%8A%E5%86%85%E7%BD%AE%E5%AF%B9%E8%B1%A1%E7%9A%84%E7%AE%80%E5%8D%95%E4%BB%8B%E7%BB%8D/> (referer: https://jcoffeezph.top/)
2018-11-19 11:03:00 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://jcoffeezph.top/2018/10/27/ArrayList%E5%92%8CLinkedList%E7%94%A8%E6%B3%95%E7%AE%80%E6%9E%90/> (referer: https://jcoffeezph.top/)
2018-11-19 11:03:00 [scrapy.core.scraper] DEBUG: Scraped from <200 https://jcoffeezph.top/2018/11/05/jsp%E5%9F%BA%E6%9C%AC%E8%AF%AD%E6%B3%95%E5%8F%8A%E5%86%85%E7%BD%AE%E5%AF%B9%E8%B1%A1%E7%9A%84%E7%AE%80%E5%8D%95%E4%BB%8B%E7%BB%8D/>
{'author': ['ForMe'], 'time': ['2018-11-05'], 'title': ['jsp基本语法及内置对象的简单介绍']}
2018-11-19 11:03:01 [scrapy.core.scraper] DEBUG: Scraped from <200 https://jcoffeezph.top/2018/10/27/ArrayList%E5%92%8CLinkedList%E7%94%A8%E6%B3%95%E7%AE%80%E6%9E%90/>
{'author': ['ForMe'],
'time': ['2018-10-27'],
'title': ['ArrayList和LinkedList用法简析']}
2018-11-19 11:03:01 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://jcoffeezph.top/2018/10/29/java%E5%AE%9E%E7%8E%B0%E9%93%BE%E8%A1%A8%E7%9A%84%E7%AE%80%E5%8D%95%E6%93%8D%E4%BD%9C/> (referer: https://jcoffeezph.top/)
2018-11-19 11:03:01 [scrapy.core.scraper] DEBUG: Scraped from <200 https://jcoffeezph.top/2018/10/29/java%E5%AE%9E%E7%8E%B0%E9%93%BE%E8%A1%A8%E7%9A%84%E7%AE%80%E5%8D%95%E6%93%8D%E4%BD%9C/>
{'author': ['ForMe'], 'time': ['2018-10-29'], 'title': ['java实现链表的简单操作']}
2018-11-19 11:03:01 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://jcoffeezph.top/2018/10/30/java-IO%E5%AD%97%E7%AC%A6%E6%B5%81%E4%B8%8E%E5%AD%97%E8%8A%82%E6%B5%81%E7%AE%80%E5%8D%95%E4%BD%BF%E7%94%A8%E7%A4%BA%E4%BE%8B/> (referer: https://jcoffeezph.top/)
2018-11-19 11:03:01 [scrapy.core.scraper] DEBUG: Scraped from <200 https://jcoffeezph.top/2018/10/30/java-IO%E5%AD%97%E7%AC%A6%E6%B5%81%E4%B8%8E%E5%AD%97%E8%8A%82%E6%B5%81%E7%AE%80%E5%8D%95%E4%BD%BF%E7%94%A8%E7%A4%BA%E4%BE%8B/>
{'author': ['ForMe'], 'time': ['2018-10-30'], 'title': ['java IO字符流与字节流简单使用示例']}
2018-11-19 11:03:01 [scrapy.core.engine] INFO: Closing spider (finished)
2018-11-19 11:03:01 [scrapy.extensions.feedexport] INFO: Stored json feed (12 items) in: scrapy.json
2018-11-19 11:03:01 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 4772,
'downloader/request_count': 15,
'downloader/request_method_count/GET': 15,
'downloader/response_bytes': 635577,
'downloader/response_count': 15,
'downloader/response_status_count/200': 14,
'downloader/response_status_count/404': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 11, 19, 3, 3, 1, 726464),
'item_scraped_count': 12,
'log_count/DEBUG': 28,
'log_count/INFO': 8,
'request_depth_max': 2,
'response_received_count': 15,
'scheduler/dequeued': 14,
'scheduler/dequeued/memory': 14,
'scheduler/enqueued': 14,
'scheduler/enqueued/memory': 14,
'start_time': datetime.datetime(2018, 11, 19, 3, 2, 57, 810300)}
2018-11-19 11:03:01 [scrapy.core.engine] INFO: Spider closed (finished)
|
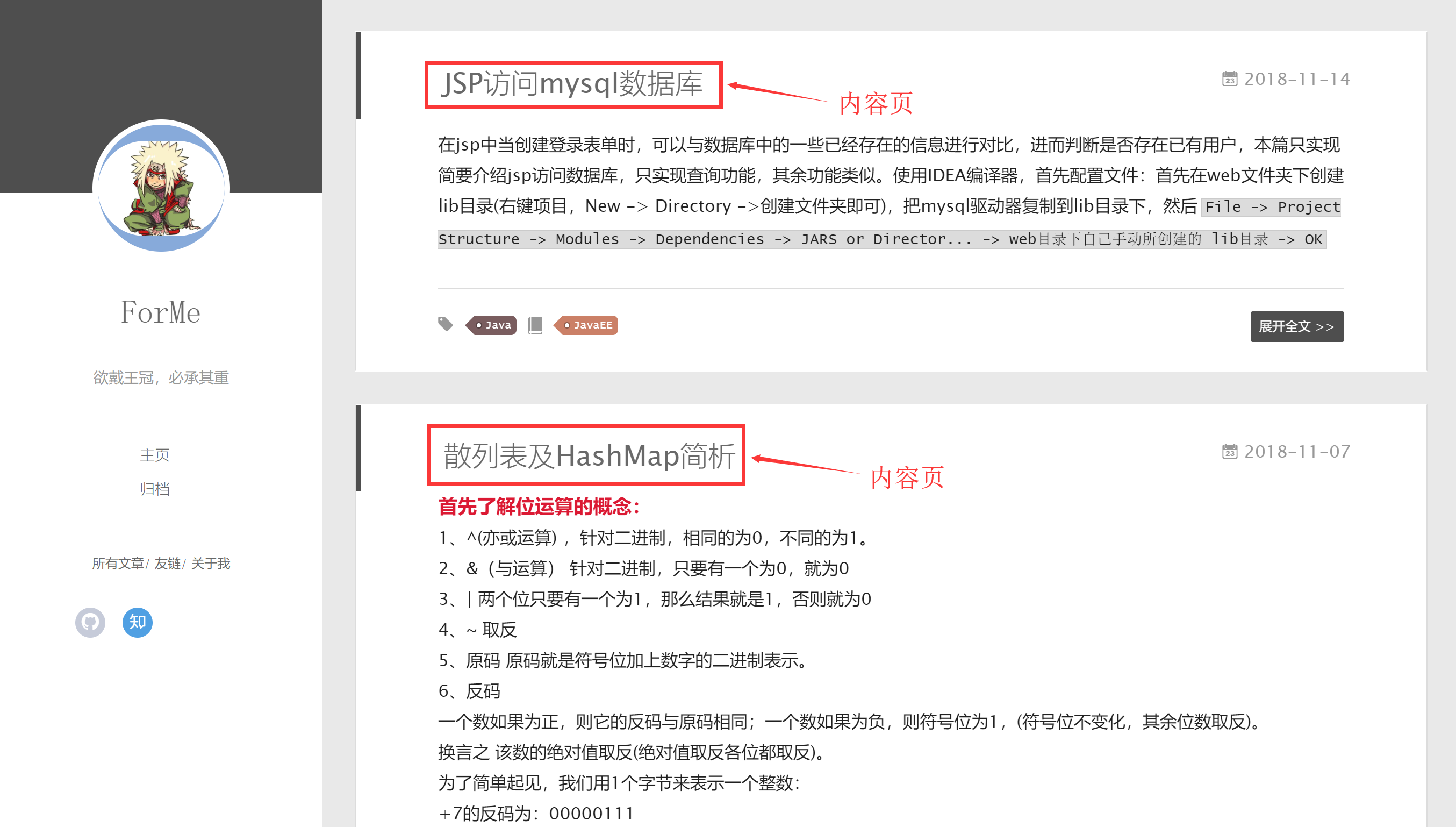
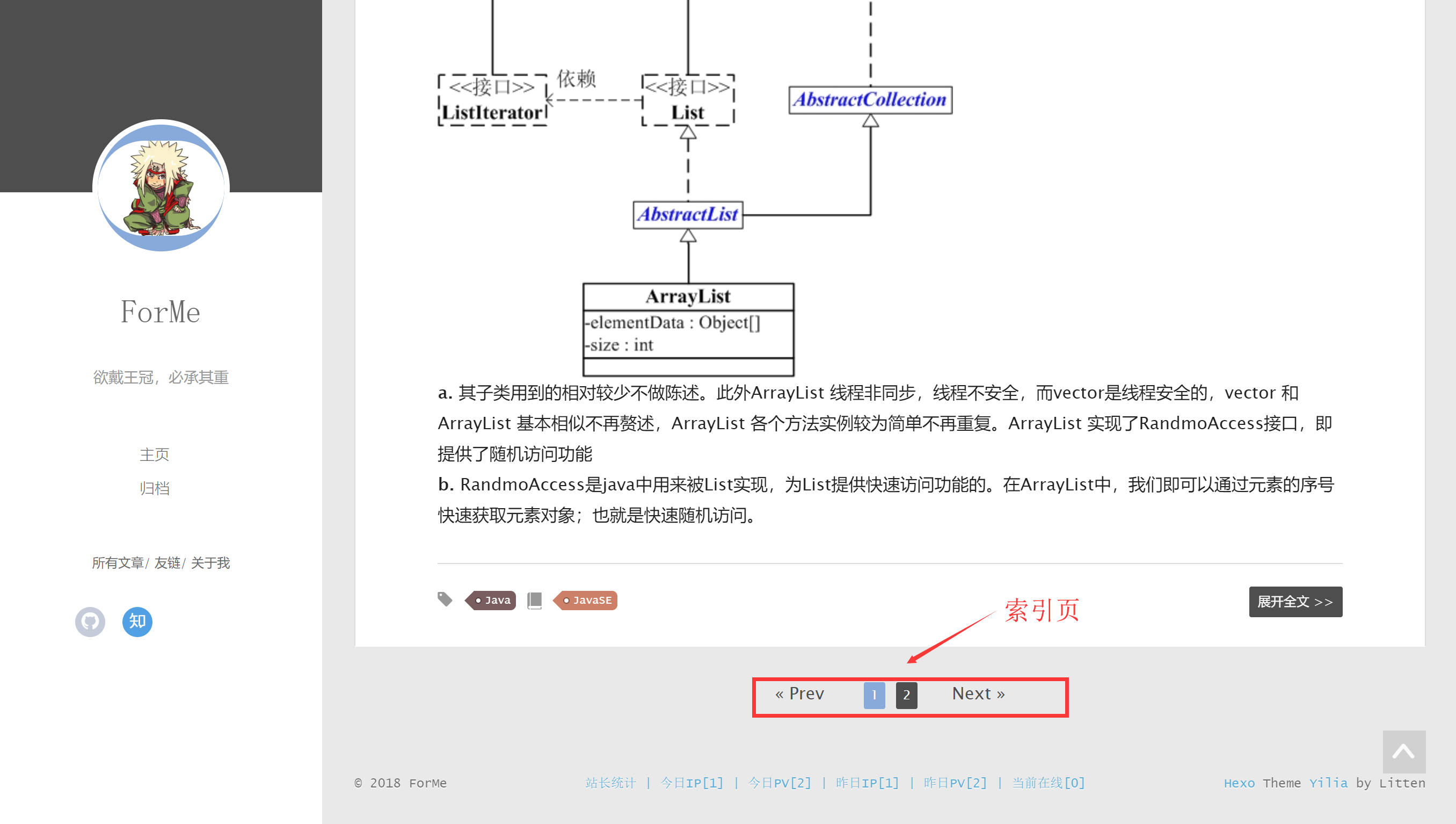 一个典型的索引页会包含许多到博客的链接,以及一个能够让你从一个索引页前往另一个索引页的分页系统。
一个典型的索引页会包含许多到博客的链接,以及一个能够让你从一个索引页前往另一个索引页的分页系统。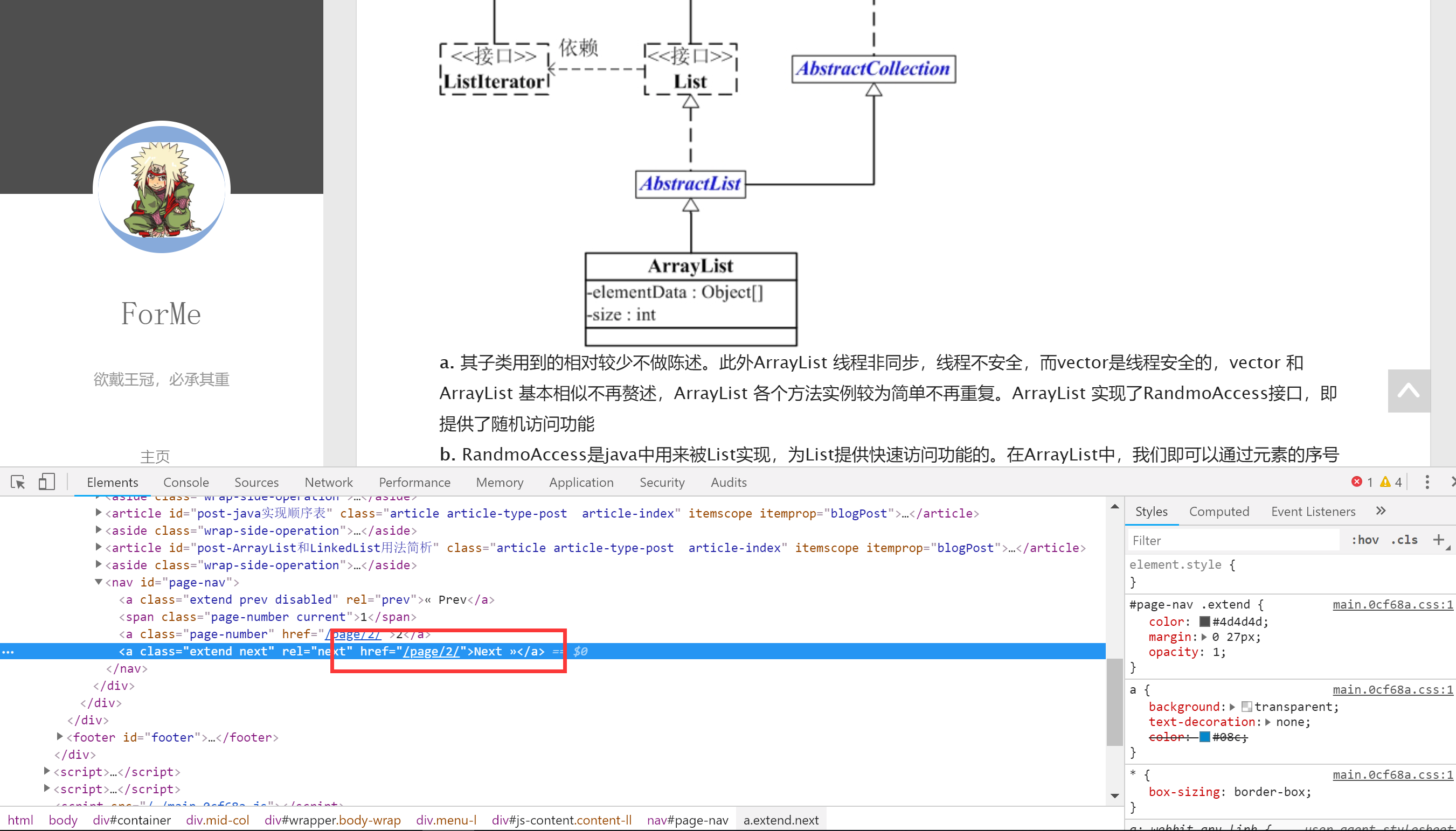 因此我们只需要使用一个使用的Xpath表达式
因此我们只需要使用一个使用的Xpath表达式
 Xpath表达式:
Xpath表达式: