我的推荐算法之路(7):MiNet
一、引言
1.1 跨域推荐的概念
首先要引入“跨域推荐”的概念。什么是”域“呢?简单来说,可以把它看作是通过某种方式聚集在一起的集合。比如可以把新闻app中的某一个板块当做一个域,也可以是b站的鬼畜区,舞蹈区等等。当然我们也可以扩大域的概念,把短视频整体当成一个域。这些定义应该都是可以的,域的概念其实可大可小。
那什么叫”跨域“呢?可能常见的推荐场景都是单域推荐比较多,也就是”游戏“只推荐”游戏“类的东西,它基于的数据也都是游戏用户本身的东西。但什么是”跨域推荐“呢?比如,我要给“鬼畜区”推荐东西,但是使用的数据不只是鬼畜区自己的,它还包括了”舞蹈区“,”数码区“,”游戏区“等其他域产生的数据。
对于此,我们要定义两个”域“的概念:”源域“和”目标域“,我们要优化、提升的目标叫做”目标域“,比如我们要优化”鬼畜区“的CTR,那么“鬼畜区”就是“目标域”。而”源域“相当于是辅助的部分,我们会把“舞蹈区”,“数码区”等看做是“源域”。
1.2 跨域推荐的细节
跨域推荐实际是有一种前提的,就是基于重叠(overlap)。为什么会有跨域?那是因为有一部分的特征也好、用户也好、物品也好,能够有一些重叠,通过重叠的部分找到两个域之间的一些关联,共分为以下四种情况。
- 用户与物品之间没有都没有交集;
- 两个域的用户有部分交集,但是物品没有交集。这种情况可以理解成鬼畜用户和舞蹈用户会有部分交集,这部分用户他们既访问了鬼畜区的视频又去舞蹈区看了小姐姐;
- 两个域的用户没有交集,但是物品有部分重合。一种可能的情况:youtube和b站的用户在法定情况下是不一样的,但是b站的部分内容又是从youtube上搬运过来的;
- 这个场景的重合度就比较高了,不论是用户还是物品都有一定程度上的重叠,这在b站上也是很常见的,比如自制区的视频同时也是数码区的视频。
原文链接:MiNet:Mixed Interest Network for Cross-Domain Click-Through Rate Prediction
二、模型设计
2.1 数据集
本文基于UC头条的应用场景,将新闻feed流作为源域,广告作为目标域。

2.2 结构设计
为了更好的利用好跨域数据,文中对三种不同的user interest进行建模:
跨域长期兴趣(Long-term interest across domains):用户的profile feature能反映出他长期的、固有的兴趣。通过跨域数据(用户交互过的所有的新闻和广告记录)可以学习出一个包含更多语义信息和可信度更高的user embedding。简单来说,就是通过用户的基本信息建模用户的内在长期兴趣。
源域短期兴趣(Short-term interest from the source domain):对于每个待预估的广告,都会有一个源域的短期用户兴趣与之关联,尽管广告和新闻的内容可能是完全不同,但其中很可能会存在一个确定的相关性比,如看了娱乐新闻后的用户可能会去点击游戏广告。基于这种相关性,我们能把源域的有用信息迁移到目标域来。简单来说就是对用户在源域的短期行为进行建模。
目标域短期兴趣(Short-term interest from the target domain):这个不言而喻了,就不多阐述了,简单来说就是对用户在目标域的短期行为进行建模。
尽管上面的三种user interest看起来可行性很高,但依然存在几个问题:
- 不是所有交互过的新闻都和目标广告有关系
- 同样,也不是所有交互过的广告都和目标广告有关系
- 模型必须能把信息从源域迁移到目标域
- 对于每个目标广告,三种用户兴趣的重要性是不一样的
- 用户兴趣向量的维度可能不一样
为了解决这些问题,提出MiNet模型,模型结构如下:
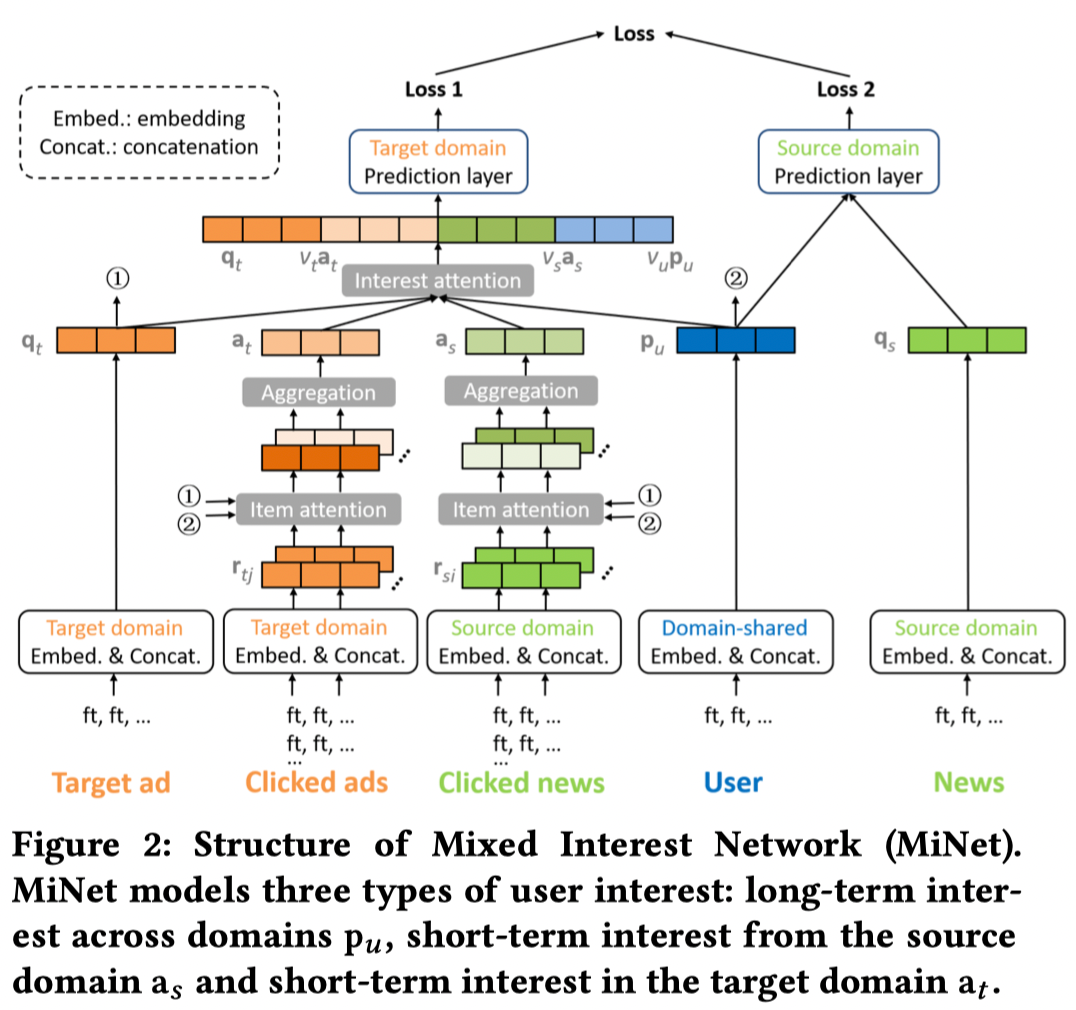
2.3 详细说明
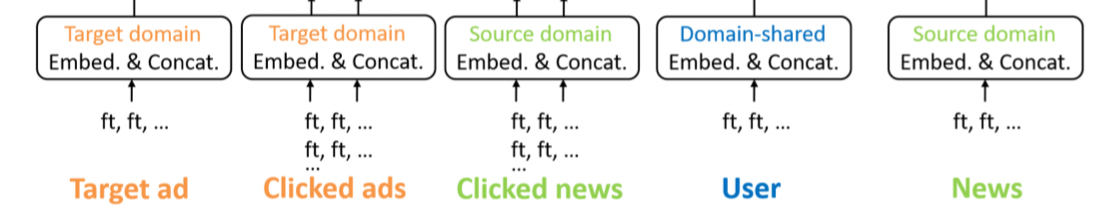
2.3.1 Embedding层
对于用户、新闻、广告来说,其某些特征可能如下表所示:
| type | feature |
|---|---|
| User information | user ID, city, age… |
| Ad information | creative ID, campaign ID, title… |
| News information | creative ID, campaign ID, title… |
以上表中的city特征为例,若对其进行one-hot编码之后直接输入到模型当中,结果往往是非常糟糕的,因为其one-hot向量是高度稀疏的,因此我们需要对其进行降维。正如大部分模型那样,这里同样使用了Embedding技术。在对每个特征Embedding之后,我们得到了相较之前维度较少的特征向量,再对各个特征的Embedding向量进行拼接之后,作为模型的输入并准备下一步的工作。
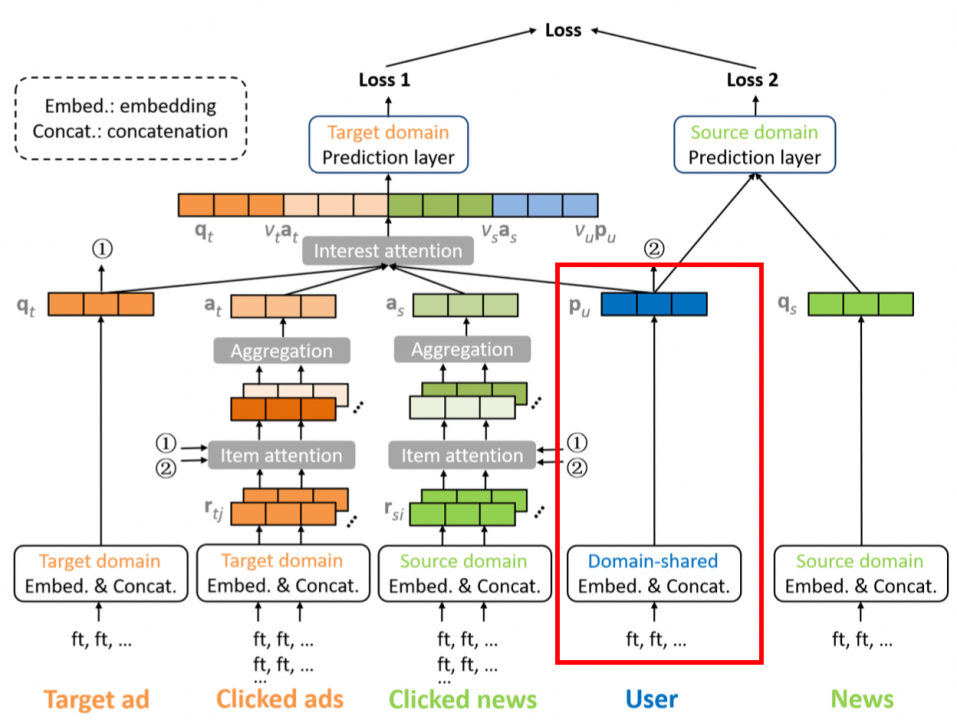
2.3.2 跨域长期建模
用户的profile feature能反映出他长期的、固有的兴趣,⽐如20岁左右的男性⽤户可能对体育赛事或者游戏类的资讯或者⼴告⽐较感兴趣。通过跨域数据(用户交互过的所有的新闻和广告记录)可以学习出一个包含更多语义信息和可信度更高的user embedding。简单来说,就是通过用户的基本信息建模用户的内在长期兴趣。这⾥主要做法是将⽤户ID、⽤户性别、⽤户所在地域、⽤户的⼿机设备等embedding向量进⾏拼接,输出为 \(P_u\)。例如⽤户ID为123,城市为北京,男性⽤户,使⽤苹果⼿机,得到的⻓期兴趣表示为:
\[P_u=[e_{u123}||e_{BJ}||e_{male}||e_{ios}]\]
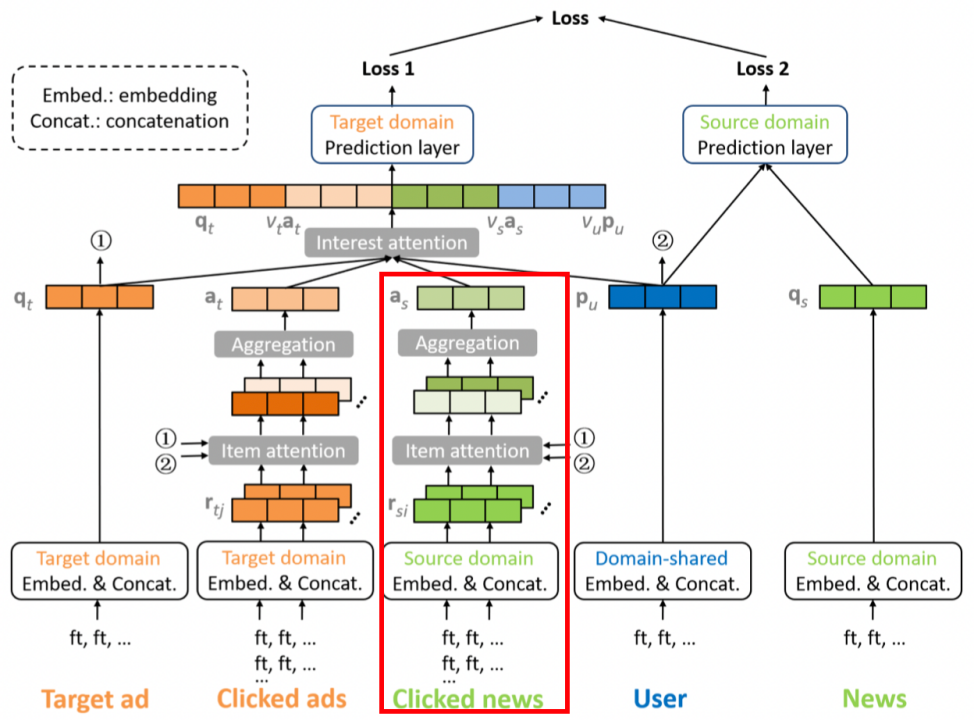
2.3.3 源域短期兴趣建模
对于每个待预估的广告,都会有一个源域的短期用户兴趣与之关联。尽管广告和新闻的内容可能是完全不同,但其中很可能会存在一个确定的相关性比,如看了娱乐新闻后的用户可能会去点击游戏广告。基于这种相关性,我们能把源域的有用信息迁移到目标域来。简单来说就是对用户在源域的短期行为进行建模。
2.3.3.1 Item attention
首先,定义\[\widetilde{a_i}=h_s^TReLU(W_s[r_{si}||q_t||p_u||Mr_{si}\odot{q_t}])\]
- \(r_{si}\) 是源域被点击新闻embedding并拼接后的特征向量;
- \(q_t\) 是目标域目标广告embedding并拼接后的特征向量;
- \(p_u\) 是用户长期兴趣向量;
- \(Mr_{si}\odot{q_t}\) 中,\(M\) 是待学习的矩阵,其将 \(r_{si}\) 映射到目标域空间中与\(q_t\) 作元素积;
2.3.3.2 Aggregation
通过softmax公式对 \(\widetilde{a_i}\) 进行映射\[a_i =\frac{exp(\widetilde{a_i})}{\sum{exp(\widetilde{a_i})}}\]
并线性加权得到最后的 \(a_s\):\[a_s=\sum{a_ir_{si}}\]
2.3.4 目标域短期兴趣建模
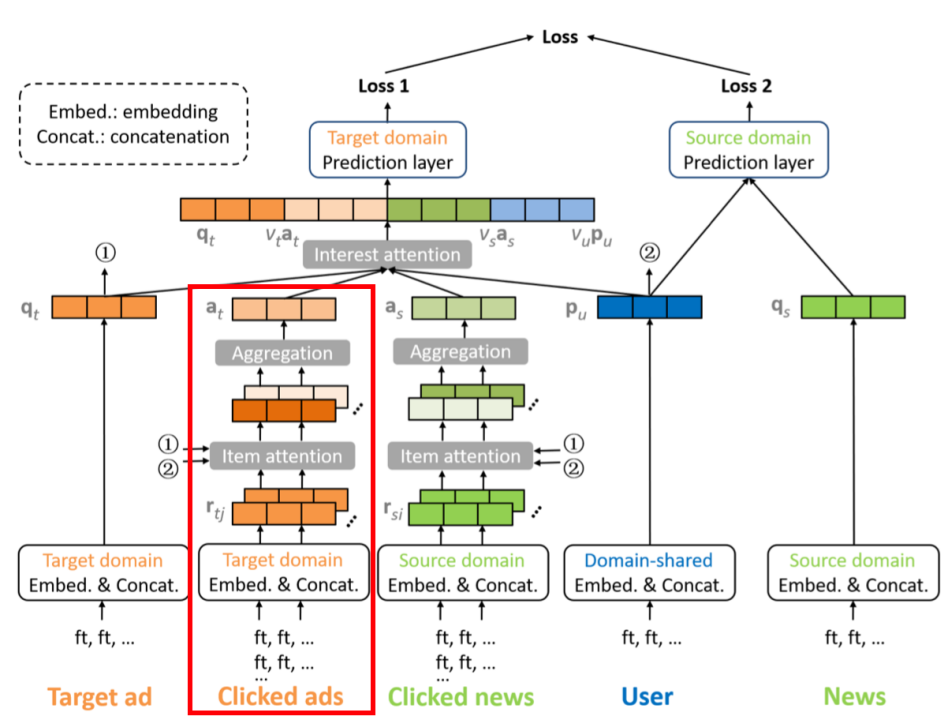
2.3.4.1 Item attention
首先,定义\[\widetilde{\beta_j}=h_t^TReLU(W_t[r_{tj}||q_t||p_u||r_{tj}\odot{q_t}])\]
与源域短期兴趣建模唯一的区别就是 \(r_{tj}\), \({q_t}\) 都是目标域的向量,不需要训练映射矩阵。
2.3.4.2 Aggregation
通过softmax公式对 \(\widetilde{\beta_j}\) 进行映射
\[\beta_j =\frac{exp(\widetilde{\beta_j})}{\sum{exp(\widetilde{\beta_j})}}\]
并线性加权得到最后的 \(a_t\):\[a_t=\sum{\beta_jr_{tj}}\]
2.3.5 Interest Attention层
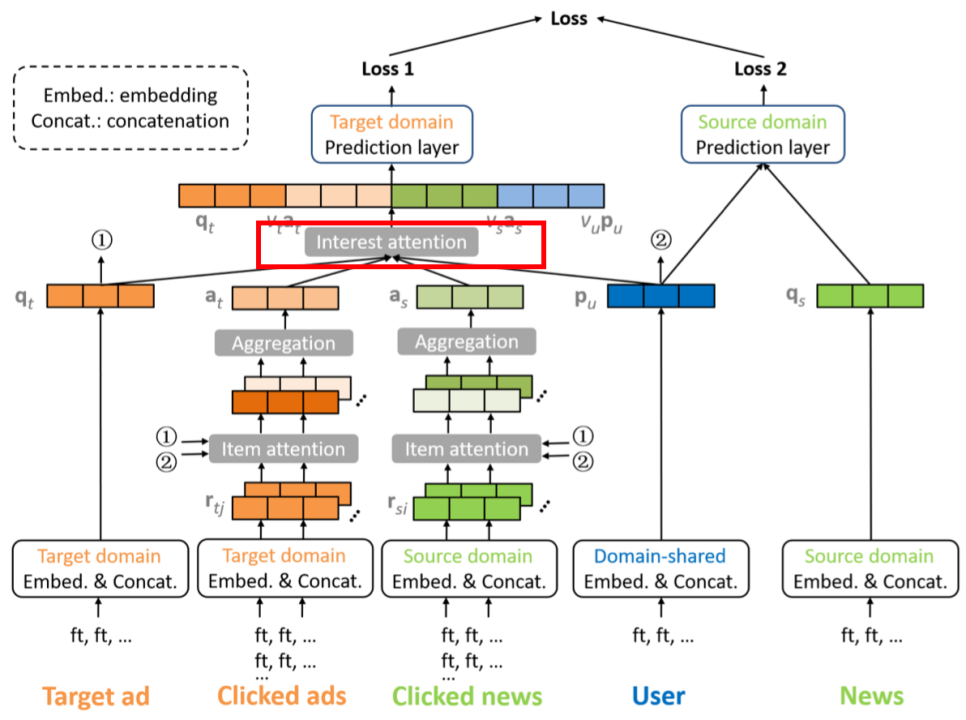
最终,输入到预测层的向量 \(m_t=[q_t||v_up_u||v_sa_s||v_ta_t]\)
其中,\[v_u=exp(g^T_uReLU(V_u[q_t||p_u||a_s||a_t])+b_u)\]
\[v_s=exp(g^T_sReLU(V_s[q_t||p_u||a_s||a_t])+b_s)\]
\[v_t=exp(g^T_tReLU(V_t[q_t||p_u||a_s||a_t])+b_t)\]
2.3.6 Prediction层和Loss函数
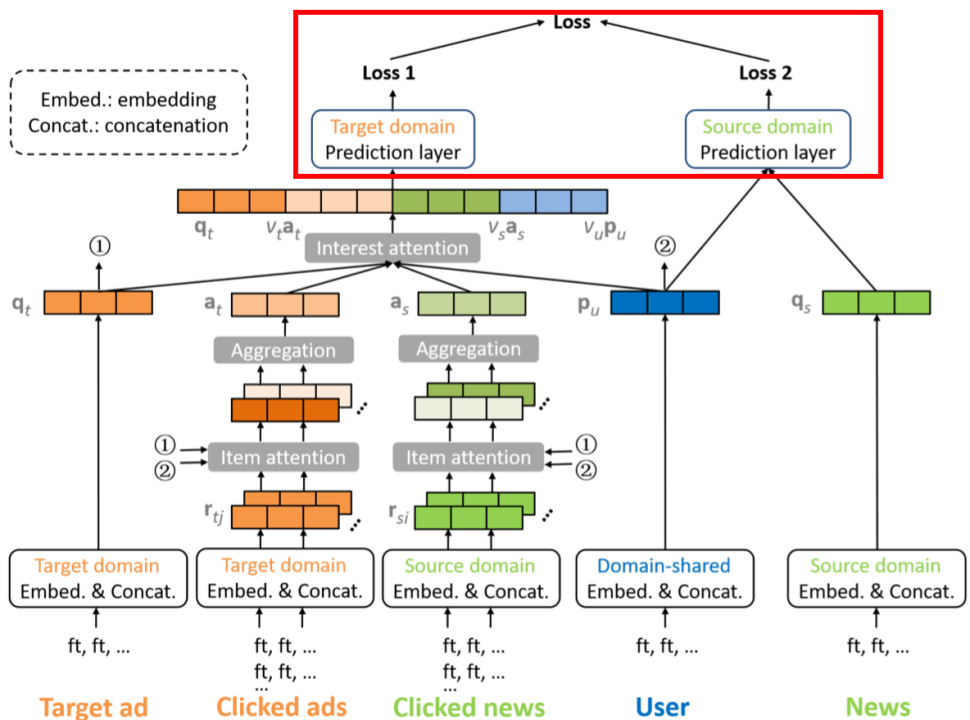
预测层是一个多层的全连接神经网络,其输出是经过sigmoid函数映射后的 [0, 1] 值。\(MiNet\) 采用了辅助任务,通过使用 \(q_s\) 向量促进对 \(p_u\) 向量的训练,并将其通过预测层。
最终模型的损失函数包括两部分:\(loss1\) 和 \(loss2\),分别记为 \(loss_t\) 和 \(loss_s\) ,每个 \(loss\) 都是用交叉熵作为损失函数,最终的损失函数 \(loss\) 如下:
\[loss=loss_t+\gamma loss_s\]
其中,\(\gamma\) 是平衡因子。
三、跨域推荐优缺点
优势:
- 首先,它可以用来解决一部分冷启动的问题。目标域的新用户很可能是源域的旧用户,那么将源域的信息拿过来辅助提升推荐的效果,能一定程度上解决冷启动;
- 第二点就是提升目标域的推荐效果,这个也是跨域推荐的主要目的;
- 第三个优势是多样性。因为跨域推荐同时参考了多个域的特征,自然而然会对推荐结果的多样性进行一定的优化。最终,它还会反作用于源域,能够实现源域的推荐与目标的域推荐效果的共同提升。
劣势:
- 跨域推荐还需要考虑一定的权衡,因为跨域必然会导致数据的稀疏,处理不当可能会有反作用。
四、参考链接
- https://zhuanlan.zhihu.com/p/221719082