Scrapy框架(八) 利用Scrapy爬取数据绘制词云图片
前言
偶然间看到了利用Python绘制词云图,一时兴起,睡意全无,导致现在已经深夜两点多了一个人默默坐在宿舍的客厅里敲着代码。现在的天气是真的冷啊,可有什么办法呢,我就是这么热爱学习!
哈哈哈哈hahahah。
虽然本篇博客把它归到了Scrapy里面,但是其大部分内容还是和绘图有关的(其实也没多少)。我们仅仅利用Scrapy爬取网上的相关数据做成一份单词表就够了,话不多说,直接正题叭~
****** ### 一、利用Scrapy爬取数据
应该是很熟练的一个操作了叭,可我还是掉进了很多坑,呜呜呜,wtcl。
像以前一样,新建Scrapy项目,然后创建我们的爬虫,直接上代码吧!
wordcloud.py 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24# -*- coding: utf-8 -*-
import scrapy
from urllib.parse import urljoin
class WordcloudSpider(scrapy.Spider):
name = 'wordcloud'
allowed_domains = ['web']
start_urls = ['https://movie.douban.com/subject/26752088/discussion/']
bash_url = 'https://movie.douban.com/subject/26752088/discussion/'
def parse(self, response):
URL = response.xpath('//span[@class="next"]/a//@href').extract()
for url in URL:
yield scrapy.Request(urljoin(self.bash_url,url),dont_filter=True)
for url in URL:
yield scrapy.Request(urljoin(self.bash_url,url),callback=self.parse_item,dont_filter=True)
def parse_item(self,response):
comments = response.xpath('//a[@title]/text()').extract()
for comment in comments:
yield {
'title': comment.strip()
}

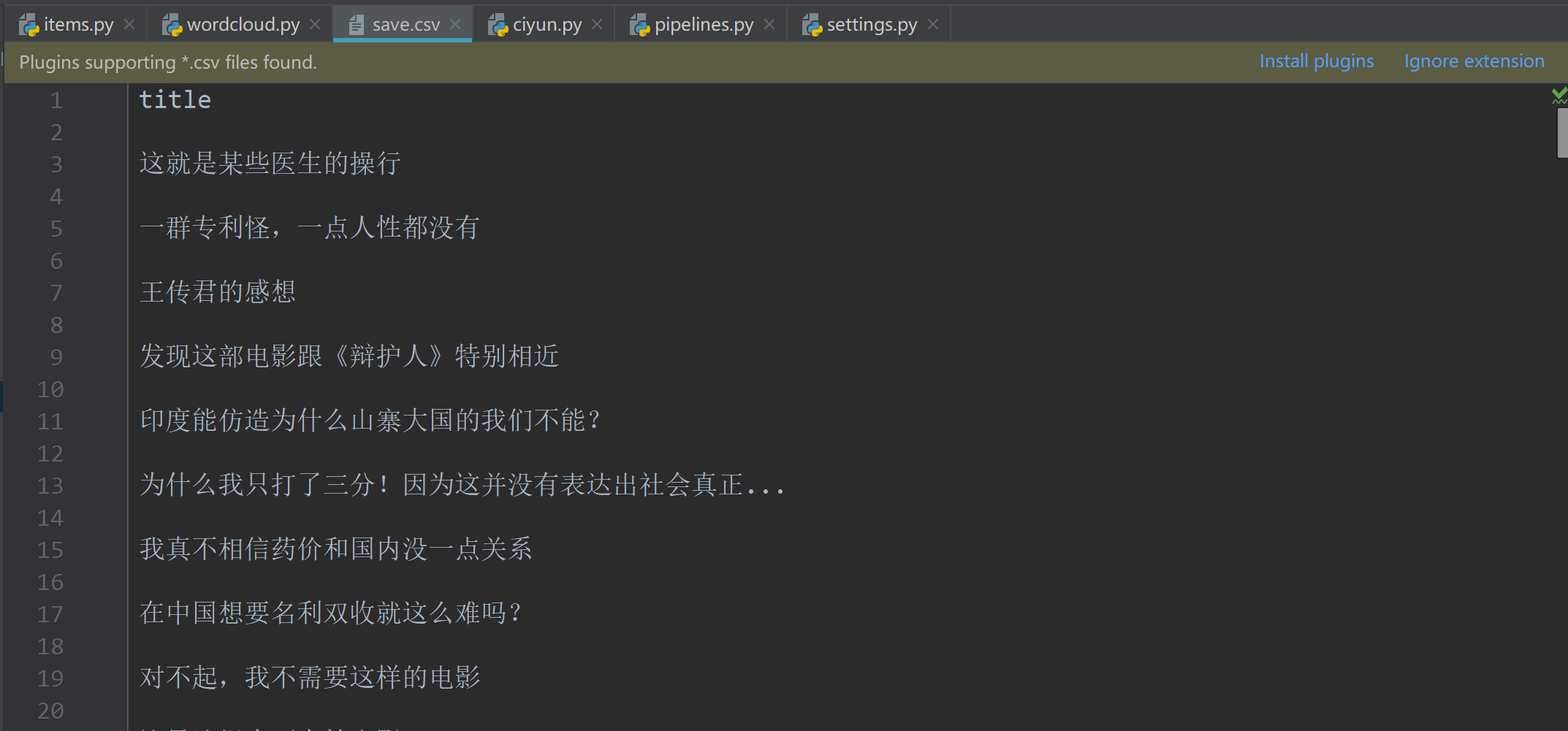
这个代码的主要目的是爬取以上页面的title值做一份单词表。
接下来我们执行命令将数据存入csv文件中: > scrapy crawl wordcloud -o save.csv -s CLOSESPIDER_ITEMCOUNT=10
save.csv
 ****** ###
二、开始绘图
****** ###
二、开始绘图 
我们首先将以上文件放入同一文件夹中: + ciyun.py 脚本 + save.csv 刚刚爬取的数据文件 + ciyun01.png 词云的背景图

先上代码: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31import os
import jieba
from PIL import Image
import numpy as np
from wordcloud import WordCloud
import matplotlib.pyplot as plt
#读取脚本所在目录
Path = os.path.dirname(__file__)
#读取csv文件并用jieba分词库制作词表
csv = open(os.path.join(Path,'save.csv'),encoding='utf-8').read()
seg_list = jieba.cut(csv,cut_all=False)
seg_list = " ".join(seg_list)
#用PIL.Image读取图片并通过numpy将之转化为数据矩阵
picture = np.array(Image.open(os.path.join(Path,'ciyun01.png')))
#生成词云
wc = WordCloud(font_path='C:\QzmVc1\STZHONGS.TTF',background_color="white",max_words=1000,max_font_size=300,mask=picture)
wc.generate(seg_list)
#通过双插值算法将数据转化为图片
plt.imshow(wc, interpolation='bilinear')
#是否显示坐标尺
plt.axis("off")
#显示图片
plt.show()
#保存图片
wc.to_file(os.path.join(Path,'C:\QzmVc1\Code\PyCharm\Python_Project\Python_Spider\Spider_Test1\WordCloud\WordCloud\ciyun_new01.png'))
关于以上代码做几点说明: >
1.os.path.dirname(__file__)
是当前py文件所在的文件目录,不包含py文件 > > 2.打开csv文件设置的
encoding=‘utf-8’ 是为了将数据显示为中文 > >
3.WordCloud中设置了字体、字号、单词个数、图片数据等参数,stzhongs.ttf是宋体,需要自行下载,不设置此参数的话词云中的单词全是小方框!
> > 4.interpolation=’bilinear’这个是双插值算法绘制图片
图片效果: 