Scrapy框架(七) 利用Scrapy进行模拟登陆
前言
初来乍到的crawler,刚开始的时候觉得所有的网站无非就是分析HTML、json数据,但是忽略了很多的一个问题,有很多的网站为了反爬虫,除了需要高可用代理IP地址池外,还需要登录。例如知乎、豆瓣等等。很多信息都是需要登录以后才能爬取,但是频繁登录后就会出现验证码(有些网站直接就让你输入验证码),这就坑了,毕竟运维同学很辛苦,该反的还得反,那我们怎么办呢?这不说验证码的事儿,你可以自己手动输入验证,或者直接用云打码平台,这里我们介绍一个利用Scrapy进行模拟登录的用法。
本片博客是对豆瓣进行模拟登陆,包括验证码的简单处理,不涉及爬取信息。 ****** ### 一、分析豆瓣登陆
- 分析豆瓣的登陆样式 豆瓣
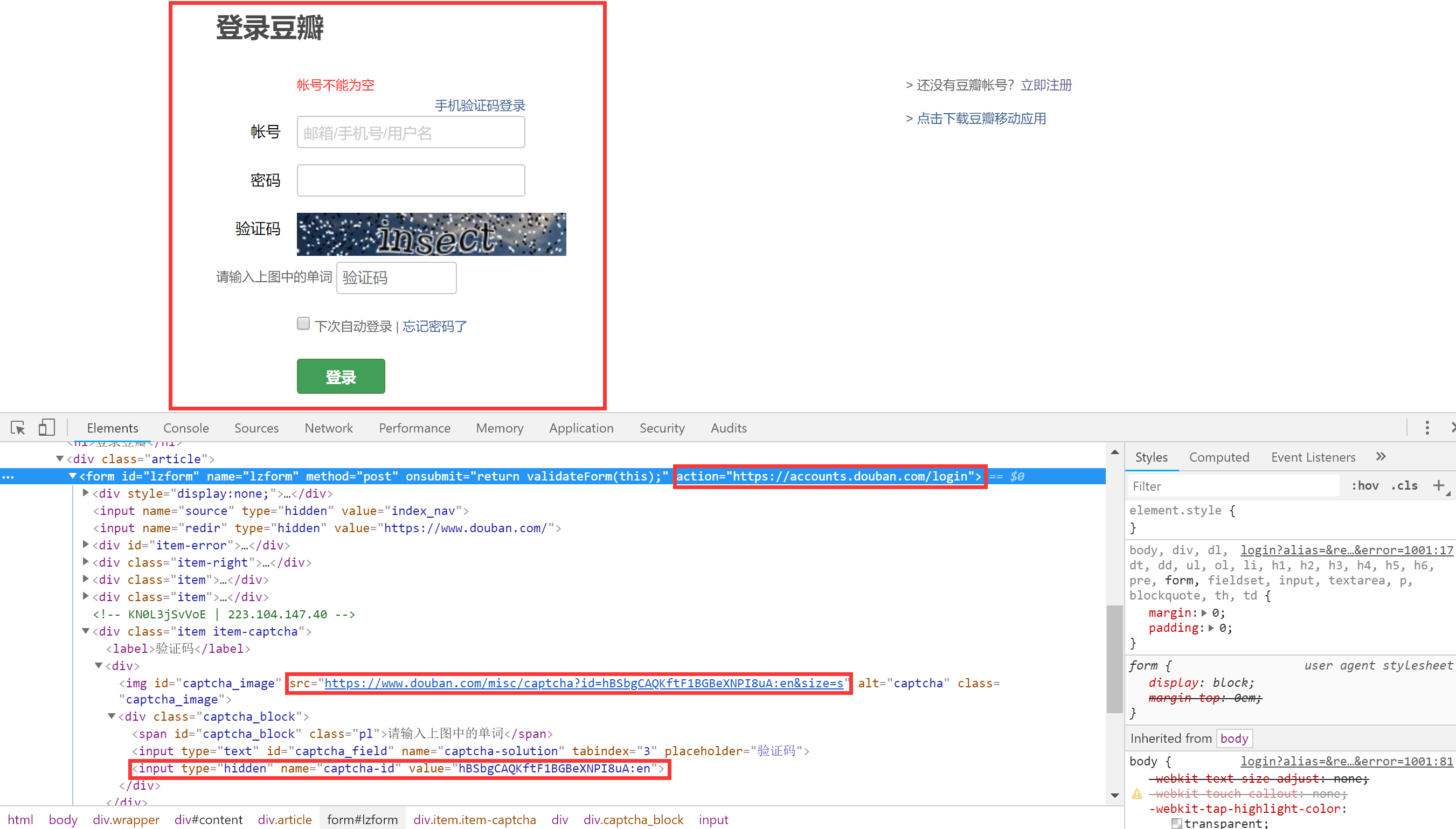
从上图可以看出:
(1)表单的action地址为: >https://accounts.douban.com/login
(2)验证码图片的地址为: >https://www.douban.com/misc/captcha?id=hBSbgCAQKftF1BGBeXNPI8uA:en&size=s
(3)captcha-id值: ><type=“hidden”name=“captcha-id”value=“hBSbgCAQKftF1BGBeXNPI8uA:en”>
- 分析豆瓣登录页的form表单登录
通过登录页我们输入错误的密码登录一次,因为只有输入错误的密码,才可以看到Network里面提交了什么样式的表单。
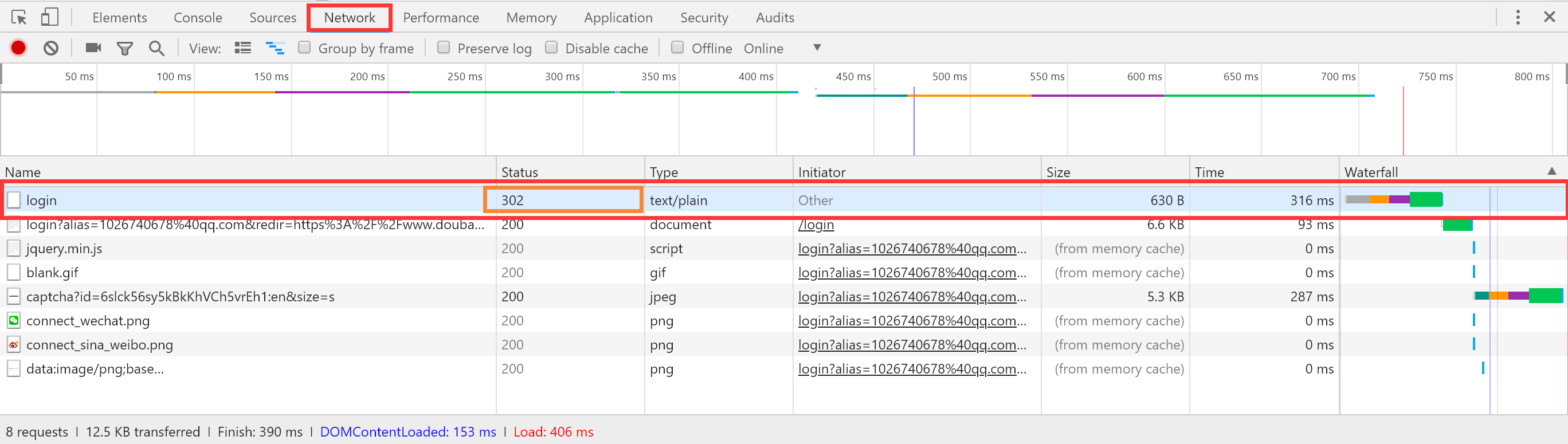
 因此我们需要通过Scrapy提取以下来填充表单: captcha-id:图片验证码id
captcha-solution:图片验证码,我们通过查看图片手动输入验证码
因此我们需要通过Scrapy提取以下来填充表单: captcha-id:图片验证码id
captcha-solution:图片验证码,我们通过查看图片手动输入验证码
其他如form_email等固定信息我们可以提前填入表单。
二、代码实现
2.1 在开始着手写代码之前,我们先了解一些关于POST请求所需要的函数:
模拟浏览器登录
start_requests(): 可以返回一个请求给爬虫的起始网站,这个返回的请求相当于start_urls,start_requests()返回的请求会替代start_urls里的请求。之所以利用该方法重写起始请求,是因为我们可以自定义一些解析函数;而start_urls和parse()默认解析函数是绑定在一起的。
Request(): get请求,可以设置url、cookie、回调函数等。
FormRequest.from_response(): 表单post提交。第一个参数是上一次响应cookie的response对象,其他参数有cookie、url、表单内容等。
yield Request()可以将一个新的请求返回给爬虫执行
在发送请求时cookie的操作: meta={‘cookiejar’:1}表示开启cookie记录,首次请求时写在Request()里
meta={‘cookiejar’:response.meta[‘cookiejar’]}表示使用上一次response的cookie,写在FormRequest.from_response()里
meta={‘cookiejar’:True}表示使用授权后的cookie访问需要登录查看的页面
2.2 爬虫代码实现
login.py 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67# -*- coding: utf-8 -*-
import scrapy
from urllib.request import urlretrieve
from PIL import Image
class LoginSpider(scrapy.Spider):
name = 'login'
allowed_domains = ['web']
# start_urls = ['http://web/'] 我们重写start_requests
# 设置防盗链,防止反爬
headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'}
#请求登陆页面,用meta开启cookie记录
def start_requests(self):
return [scrapy.FormRequest("https://accounts.douban.com/login",headers=self.headers,meta={'cookiejar':1},callback=self.parse_before_login,dont_filter=True)]
#登陆表单填充,查看验证码
def parse_before_login(self,response):
print("登陆前表单填充:......")
# 获取验证码的 id 和 url
captcha_id = response.xpath('//input[@name="captcha-id"]/@value').extract_first()
captcha_src_url = response.xpath('//img[@id="captcha_image"]/@src').extract_first()
if captcha_src_url is None:
print('登陆时无需验证码...')
formdata = {
"source" : "index_nav",
"form_email" : "1026740678@qq.com",
"form_password" : "xxxxxx",
}
else:
print('登陆时需要验证码...')
#通过urllib将图片下载到本地,用Pillow打开并手动输入验证码
#本地存储路径
save_path = 'C:\QzmVc1\Code\PyCharm\Python_Project\Python_Spider\Spider_Test1\SimulatedLanding\SimulatedLanding\captcha.jpeg'
#下载
urlretrieve(captcha_src_url,save_path)
#用Pillow打开图片
try:
im = Image.open(save_path)
im.show()
except Exception as e:
print(e)
captcha_solution = input("请输入验证码:")
formdata = {
"source": "index_nav",
"redir": "https: // www.douban.com /",
"form_email": "1026740678@qq.com",
"form_password": "xxxxxx",
"captcha-solution": captcha_solution,
"captcha-id": captcha_id,
"login": "登录",
}
print("正在登陆...")
# 提交表单进行登陆
return scrapy.FormRequest.from_response(response,headers=self.headers,meta={'cookiejar':response.meta['cookiejar']},formdata=formdata,callback=self.parse_after_login,dont_filter=True)
def parse_after_login(self,response):
#验证是否登录成功
account = response.xpath('//a[@class="bn-more"]/span/text()').extract_first()
if account is None:
print("登陆失败...")
else:
print("登陆成功! 账户为%s " % (account))
输入以下命令开始模拟登陆: > scrapy crawl login
运行结果:
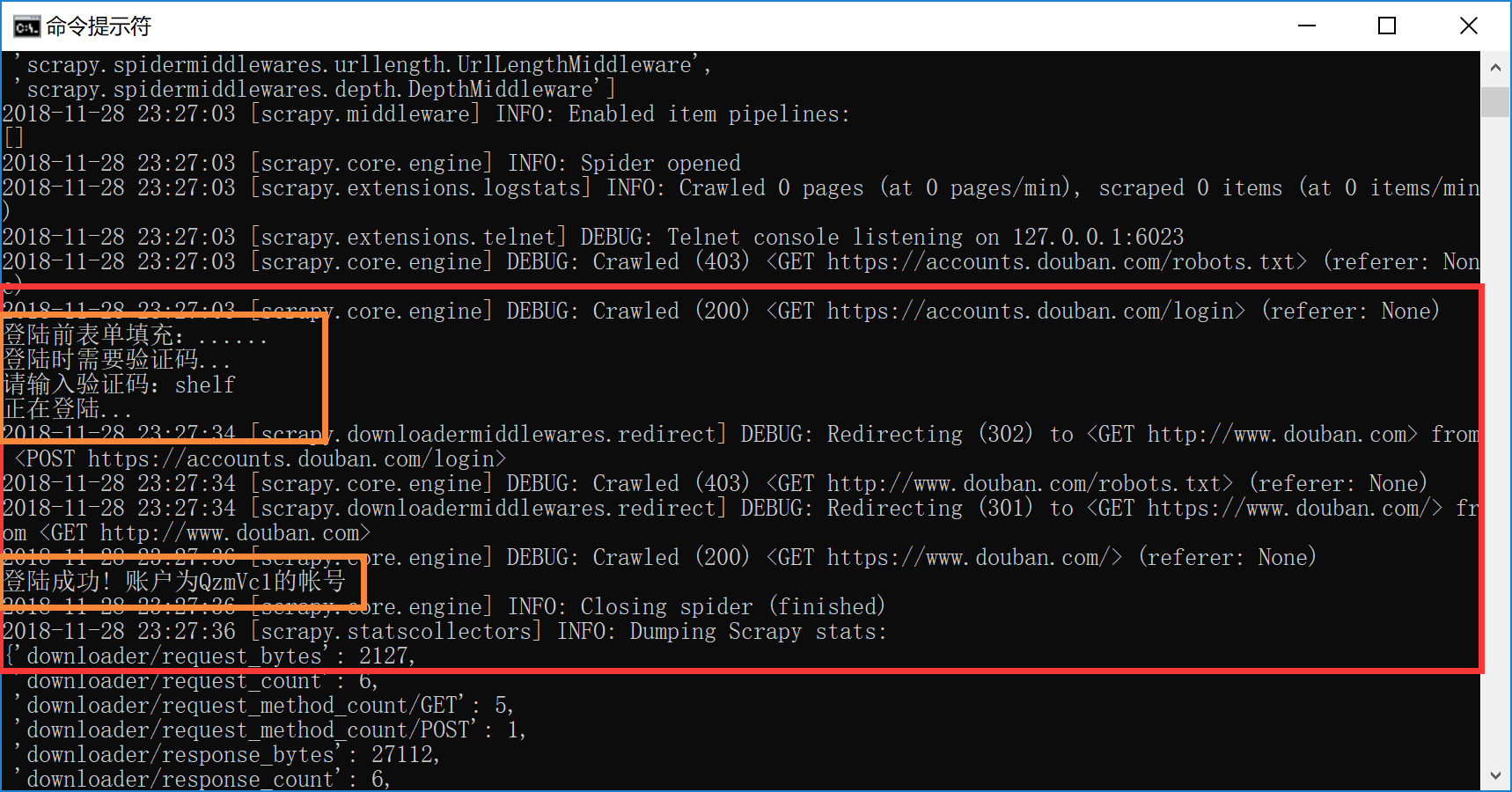
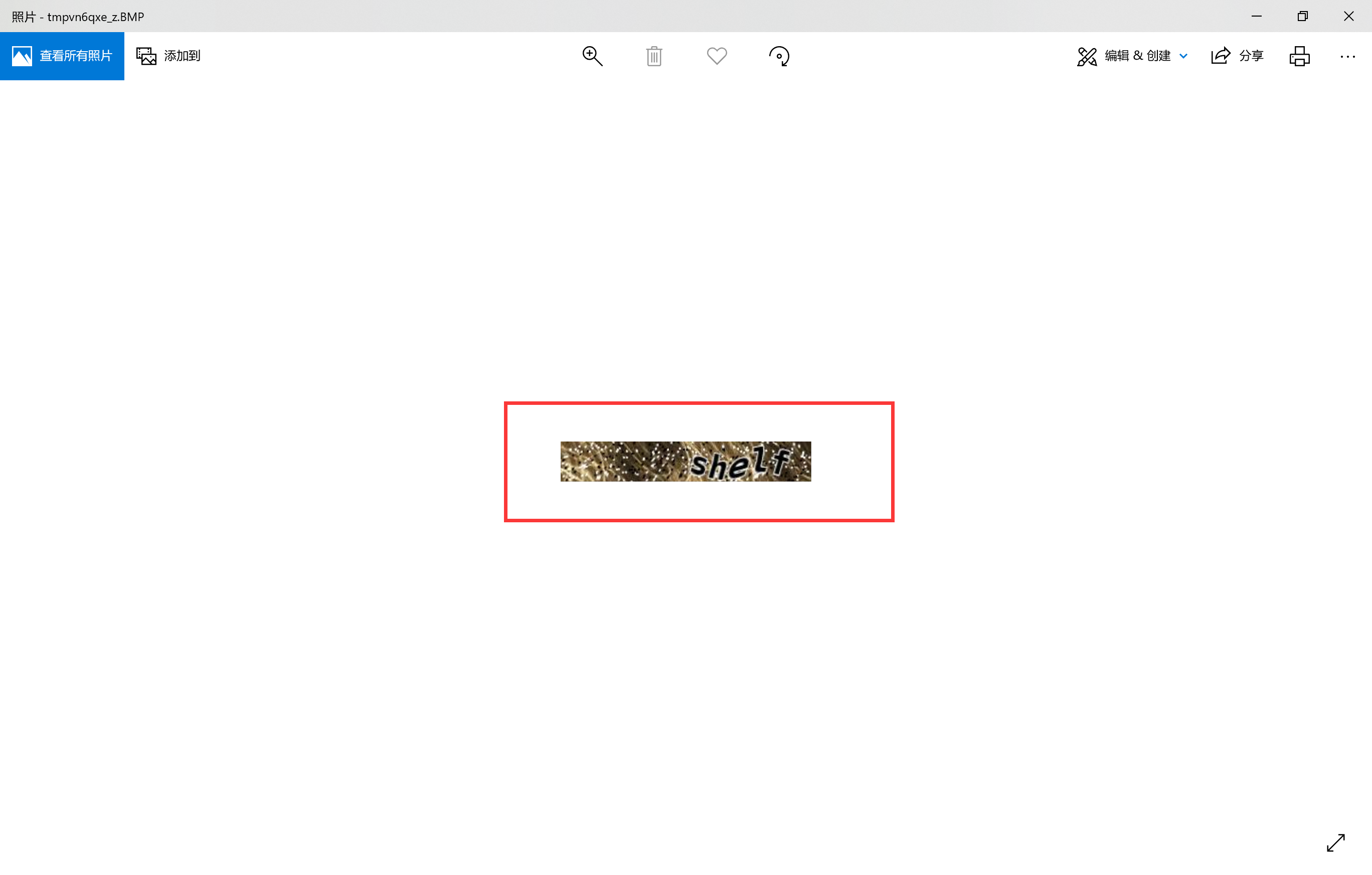
运行到验证码获取图片时它会自己蹦出来:
登陆成功!是不是很激动呢! ****** ### 三、问题处理 每次进行请求时别忘了将dont_filter设置为True!我又掉了一次坑。