# -*- coding: utf-8 -*- import scrapy from urllib.parse import urljoin from scrapy.http import Request from ImageDownloads.items import ImagedownloadsItem
classImageSpider(scrapy.Spider): name = 'image' allowed_domains = ['web'] start_urls = ['http://qzmvc1.top/']
defparse(self, response): URL1 = response.xpath('//a[@class="extend next"]//@href').extract() for url in URL1: yield Request(urljoin(response.url,url),dont_filter=True)
URL2 = response.xpath('//a[@class="article-title"]/@href').extract() for url in URL2: yield Request(urljoin(response.url,url),callback=self.parse_item,dont_filter=True)
from scrapy.pipelines.images import ImagesPipeline from scrapy.exceptions import DropItem from scrapy import Request from pymysql import cursors from twisted.enterprise import adbapi from urllib.parse import unquote import random
classImagedownloadsPipeline(ImagesPipeline): # 迭代获取图片URL链接并进行下载 defget_media_requests(self,item,info): for url in item['image_urls']: try: if'http'notin url: continue else: yield Request(url) except Exception as e: print(e)
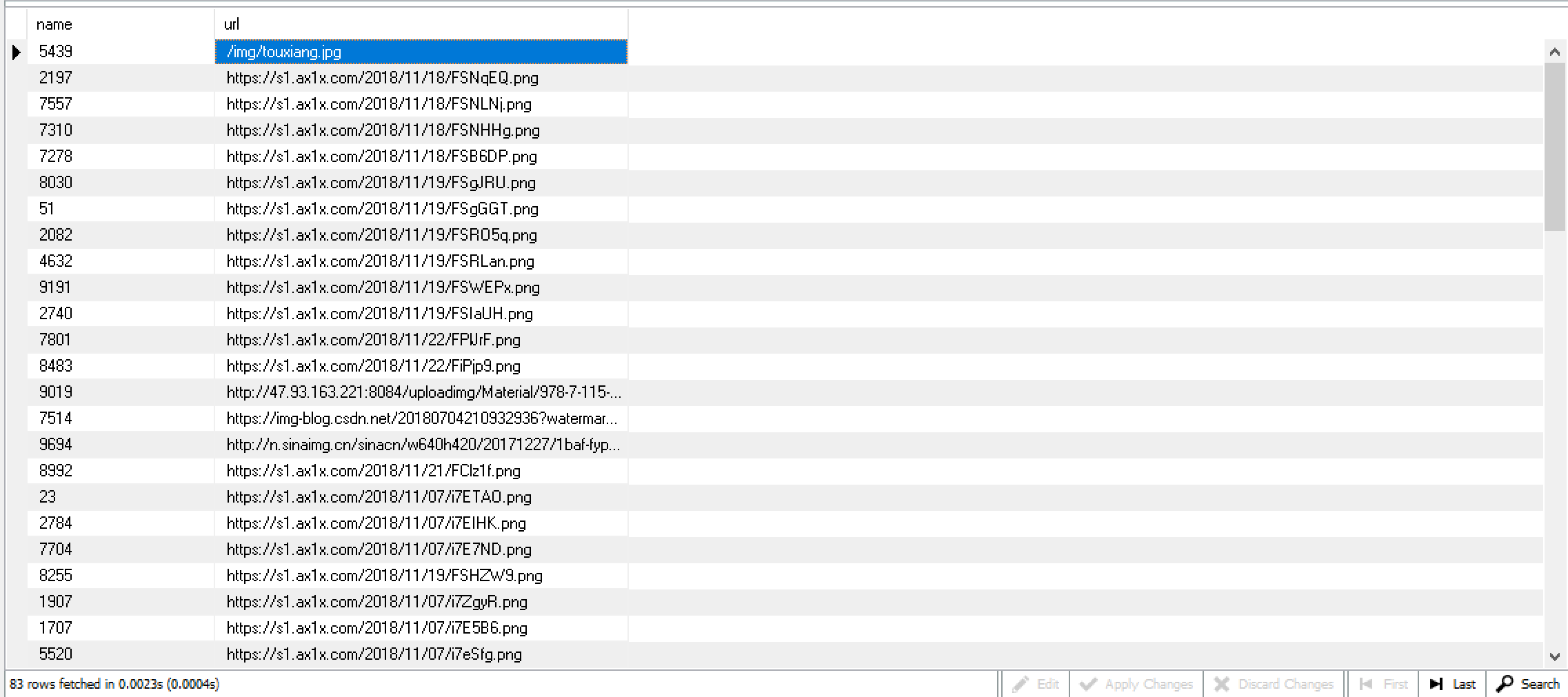
defdo_insert(self,cursor,item): sql = "insert into image(name,url) values(%s,%s);" urls = item['image_urls'] for i in urls: if i notin self.lst: cursor.execute(sql, (random.randint(0, 10000), unquote(i))) self.lst.add(i)