Scrapy框架之细数到目前为止我遇到的坑
本篇博客会在我学习Scrapy的途中不断更新,记录大大小小的我遇到的坑。直接正题。 ****** 问1:Python3.7版本使用Scrapy Shell遇到invalid syntax 答1:如果出现SyntaxError:invalid syntax,在“ from twisted.conch import manhole ”而且提示符 ‘^’ 指向async,那么很有可能是因为你的版本是Python3.7,这个版本把async变成了关键字,这个时候就需要自己动手去找到并打开 manhole.py (在错误信息里面找)这个文件,然后找到(CTRL+F)所有 “async” 关键字并修改成关键字无关的标识符如“async_” 。
问2:Scrapy爬虫提示 list index out of range 答2:extract()返回信息列表,extract()[0]显示 index out of range 错误信息,将extract()[0]换成extract_first()即可。
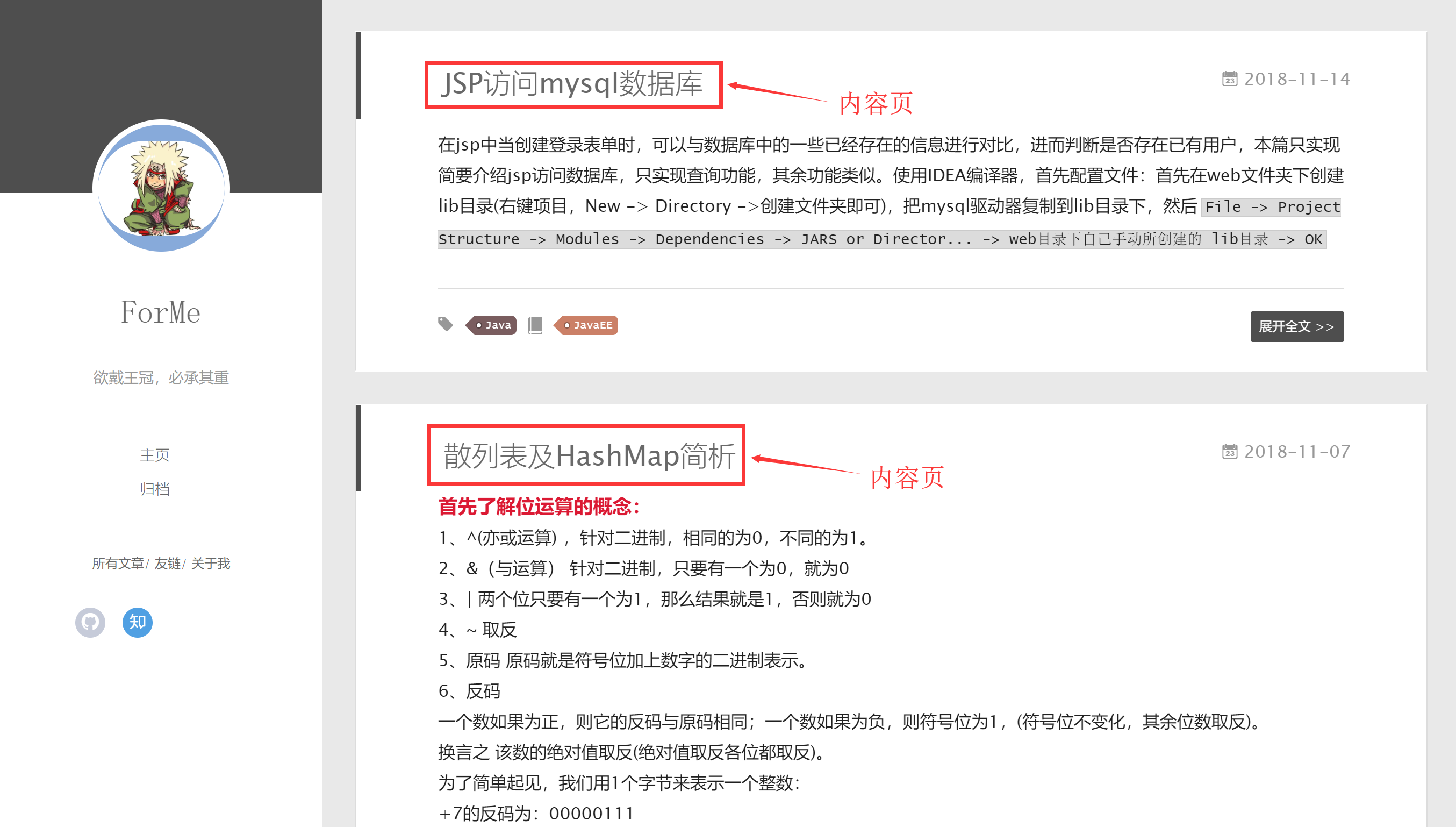
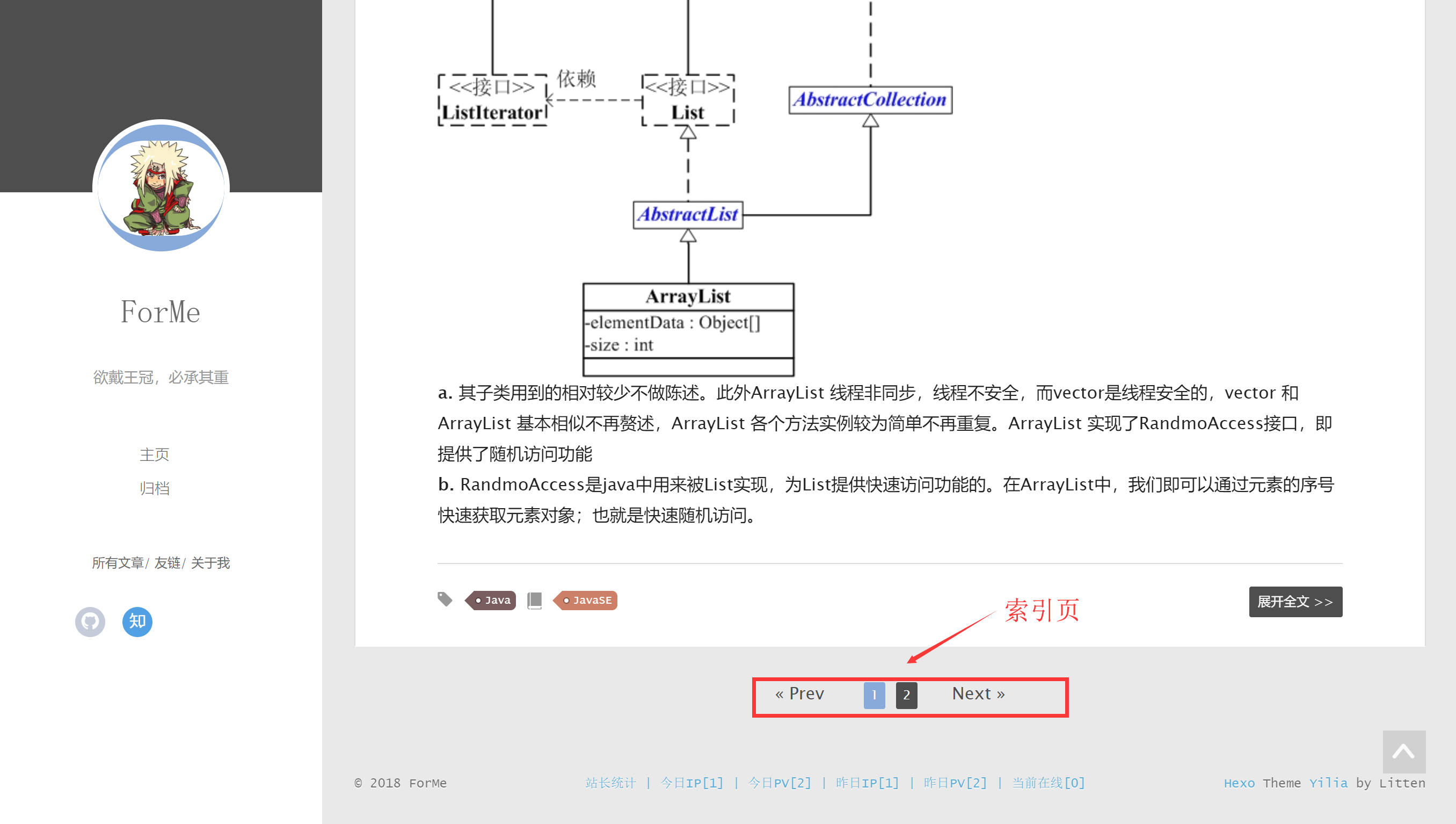 一个典型的索引页会包含许多到博客的链接,以及一个能够让你从一个索引页前往另一个索引页的分页系统。
一个典型的索引页会包含许多到博客的链接,以及一个能够让你从一个索引页前往另一个索引页的分页系统。 ### 前言
很早之前学习了《Python网络数据采集》这本爬虫入门书籍,书上基本用的是Python标准库urllib和第三方库BeautifulSoup,还有一些少量的requests库。过了这么长时间,对爬虫也不是很熟悉了。想了想以后可能会从事大数据方面的工作,本人对数据也是hin感兴趣。于是想腾出时间学习一下Scrapy框架,也趁此机会巩固一下我的爬虫能力。
### 前言
很早之前学习了《Python网络数据采集》这本爬虫入门书籍,书上基本用的是Python标准库urllib和第三方库BeautifulSoup,还有一些少量的requests库。过了这么长时间,对爬虫也不是很熟悉了。想了想以后可能会从事大数据方面的工作,本人对数据也是hin感兴趣。于是想腾出时间学习一下Scrapy框架,也趁此机会巩固一下我的爬虫能力。