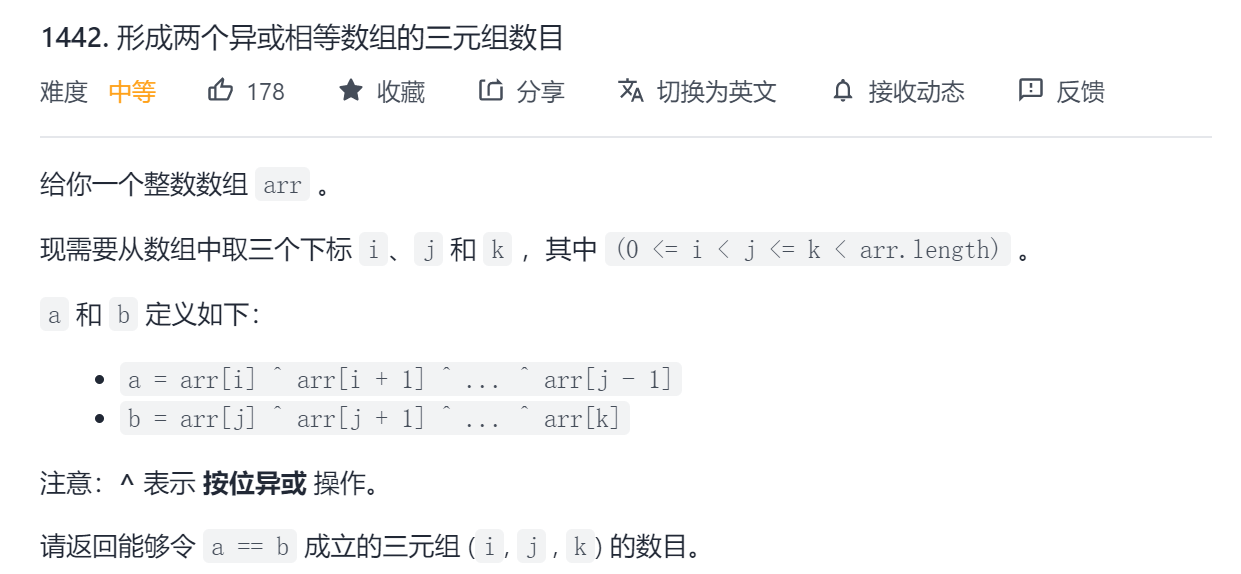
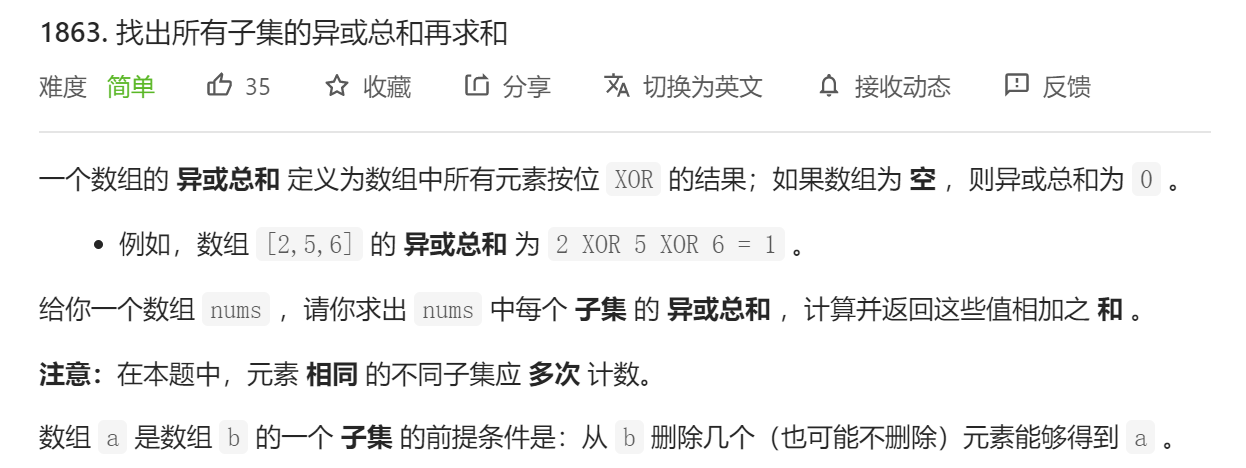
LeetCode1442:形成两个异或相等数组的三元组数目
一、题目描述
CTR预估(Click-Through Rate Prediction)是互联网计算广告中的关键环节,预估准确性直接影响公司广告收入。CTR预估中用的最多的模型是LR(Logistic Regression),LR是广义线性模型,这种线性模型很容易并行化,处理上亿条训练样本不是问题。但线性模型学习能力有限,需要大量特征工程预先分析出有效的特征、特征组合,从而去间接增强LR的非线性学习能力。
LR模型中的特征组合很关键, 但又无法直接通过特征笛卡尔积解决,只能依靠人工经验,耗时耗力同时并不一定会带来效果提升。如何自动发现有效的特征、特征组合,弥补人工经验不足,缩短LR特征实验周期,是亟需解决的问题。Facebook 2014年的文章介绍了通过GBDT(Gradient Boost Decision Tree)解决LR的特征组合问题,随后Kaggle竞赛也有实践此思路,GBDT与LR融合开始引起了业界关注。
GBDT(Gradient Boost Decision Tree)是一种常用的非线性模型,它基于集成学习中的boosting思想,每次迭代都在减少残差的梯度方向新建立一颗决策树,迭代多少次就会生成多少颗决策树。GBDT的思想使其具有天然优势可以发现多种有区分性的特征以及特征组合,决策树的路径可以直接作为LR输入特征使用,省去了人工寻找特征、特征组合的步骤。这种通过GBDT生成LR特征的方式(GBDT+LR),业界已有实践(Facebook,Kaggle-2014),且效果不错,是非常值得尝试的思路。
在仅利用单一特征而非交叉特征进行判断的情况下,有时不仅是信息损失的问题,甚至会得出错误的结论。著名的“辛普森悖论”用一个非常简单的例子,说明了进行多维度特征交叉的重要性。
在对样本集合进行分组研究时,在分组比较中都占优势的一方,在总评中有时反而是失势的一方,这种有悖常理的现象,被称为“辛普森悖论”。
假设表2-1和表2-2所示为某视频应用中男性用户和女性用户点击视频的数据。
针对协同过滤算法的头部效应较明显、泛化能力较弱的问题,矩阵分解算法被提出。矩阵分解在协同过滤算法中“共现矩阵”的基础上,加入了隐向量的概念,加强了模型处理稀疏矩阵的能力,针对性地解决了协同过滤存在的主要问题。
顾名思义,“协同过滤”就是协同大家的反馈、评价和意见一起对海量的信息进行过滤,从中筛选出目标用户可能感兴趣的信息的推荐过程。其主要分为:
CART(Classification and Regression Tree),又名分类回归树,是在ID3的基础上进行优化的决策树,CART有以下几个关键点:
